Chapter 6 Probability
6.1 Sample Spaces and Events
6.1.1 Introduction
Now is the time to take a slight detour from the study of statistics into the sister field of probability theory. Probability theory provides much of the theoretical backbone for the study of statistics. The origins of probability theory come from gambling. In particular, the first person to apply the analysis given here was Geralamo Cardano and Italian gambler in the 1500’s. Cardano was the first person to analyze the outcomes of ``games of chance’’ in a structured and mathematical way. This gave him a tremendous advantage over his competitors in 1500’s Italy. However, he was never able to fully capitalize on his advances as his family life was a 1500’s version of the Jerry Springer show.
6.1.2 Sample Spaces
Cardano’s great idea was the concept of the sample space which will denote as \(\Omega\). To determine the probability on a event occurring, Cardano’s idea is to make a list of all the possible outcomes from a random event. For example, a random event might be flipping a coin in which case the set of possible outcomes (the sample space \(\Omega\)) is given by \(\Omega=\{H,T\}\). If the random event is rolling a six-sided dice the sample space is \(\Omega=\{1,2,3,4,5,6\}\). In blackjack the sample space is \(\Omega=\{2,3,4,...21, B\}\), where the \(B\) stands for busting.
Exercise 6.1 List out the possible outcomes from flipping a coin twice.
6.1.3 Law of Sample Spaces
For the special case where all events from a random event are equally likely we can use the Law of Sample Spaces to calculate the probability of an event.
Use the Law of Samples Spaces to Calculate the probabilities below:
We can already see that the LSS turns probability calculations into a problem of counting stuff. As the numbers get larger it quickly becomes untenable to count things by hand. For example, if we try and list out all possible ways outcomes from flipping a coin ten times this would take about 84 days working for 12 hours a day! (over 3 million possibilities). In order to make better use of the LSS we need better techniques to count things.
6.2 Combinatorics
6.2.1 Basic Principle of Counting
Combinatorics just means the mathematics of counting things.
Use the basic principle of counting to find the number of outcomes for the following random experiments:
6.2.2 Permutations
In the last exercise above we had to figure out how many ways we could order the five runners. Our logic for solving this generalizes to how many ways we can order any \(N\) distinct objects.
We can use R to calculate permutations \(N!\) using the command:
In some cases we may want to know how many ways we can order a subset of elements. For example, how many four digit pins are possible if we can’t repeat the same digit more than once? Well, we have 10 choice for the first digit, 9 for the second, 8 for the third and 7 for the fourth. Therefore \(N=10\times9\times8\times7\). Notice we can also write this as \(N=10!/6!\)
6.2.3 Combinations
We now want to consider the problem of counting outcomes for the case where the order doesn’t matter. For example, we may want to find the total number of five card poker hands. Perhaps our first instinct is to use the permutations formulas from the last section. We have 52 distinct objects and we want to know how many ways we can draw five of them. This gives: \[P(52,5)=52!/47!=52\times 51\times50\times49\times48=5,997,600.\] However, their is a subtle error in our calculation. Using the permutation formula means that we care about the order the cards appear in! For example, the permutation way of counting means that the two hands: \[ 2 \heartsuit, 3 \spadesuit, 8 \clubsuit, 2 \spadesuit, \text{Ace} \diamondsuit \qquad \qquad \qquad \text{Ace} \diamondsuit, 2 \heartsuit, 3 \spadesuit, 8 \clubsuit, 2 \spadesuit \]
are being counted as separate hands! This isn’t what we really want to count as these two hands are entirely equivalent in a game of poker.
To correct this over counting, we just need to divide by the number of equivalent entries in our count. In this case we have \(5!\) poker hands which are equilvalent. Therefore, we have the total number of five card poker hands is: \[ P_5=\frac{52!}{5! 47!}=2,598,960 \] So just about 2.6 million unique five card hands. As usual we can generalize our poker analysis to hold for general collections of objects.In R we can calculate \(C(N,k)=\binom{N}{k}\) using the command:
6.3 Axioms of Probability
6.3.1 Beyond the Law of Sample Spaces
The LSS tells us that \[{P(E)}=\frac{\text{outcomes in E}}{\text{total outcomes}},\] but we have seen that the LSS doesn’t apply when the outcomes are not all equally likely. Outside of gambling scenarios not all outcomes are equally likely and the Law of Sample Spaces does not apply.
To continue to make progress we need to move beyond the Law of Sample Spaces.
6.3.2 Set Theory
To go much further we need to learn a bit of set theory. A set is just a collection of unique objects. For example, coin flip outcomes {H,T}, dice roll outcomes \(\{1,2,3,4,5,6\}\). Now lets consider the different ways we can combine sets.
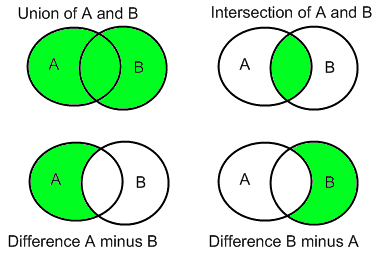
- Union of Sets: Given two sets \(A\) and \(B\) the union of \(A\) and \(B\) which we write as \(A \cup B\) consists of all the elements in \(A\) and all the elements in \(B\). For example, let \(A=\{1,2,3\}\) and \(B=\{3,4,5\}\) then \(A \cup B=\{1,2,3,4,5\}\).
Intersection of Sets: Given two sets \(A\) and \(B\) the intersection of \(A\) and \(B\) which we write as \(A \cap B\) consists of those elements which are in BOTH A and B. For example, let \(A=\{1,2,3\}\) and \(B=\{3,4,5\}\) then \(A \cap B=\{3\}\).
Difference of Sets: Given two sets \(A\) and \(B\) the A minus B written \(A\setminus B\) consists of those elements in A which are NOT also in B. For example, let \(A=\{1,2,3\}\) and \(B=\{3,4,5\}\) then \(A \setminus B=\{1,2\}\).
Subsets: We say that the set A is a subset of B written as \(A \subseteq B\) if every element of A is also in B. The symbol \(A \subseteq B\) is similair to the less than or equal to \((\leq)\) sign. It means that \(A\) is contained in \(B\) but the two sets may in fact be equal. The symbol \(A \subset B\) means that \(A\) is a proper subset of B. Meaning that there is some element of \(B\) which is not in \(A\).
Empty Set: Occasionally it is useful to have a notation for a set which has no elements in it at all. This is called the empty set and is denoted by \(\emptyset\). For example, we could say that \(\{1,2\} \cap \{9,10\}=\emptyset\)
Exercise 6.18 Let \(\Omega\) be the set of all students at Schreiner, and \(\mathbb{A}\) be the set of students in this class and let \(\mathbb{M}\) be the set of music majors at Schreiner.
- Is it true that \(\mathbb{A} \subset \Omega\)?
- What does the set \(\Omega \setminus \mathbb{M}\) contain?
- What does the set \(\mathbb{A} \cup \mathbb{M}\) contain?
6.3.3 The Axioms of Probability
The axioms of probability are sort of like the mathematical version of the declaration of independence statement: We hold these truths to be self-evident…. We can’t prove them but without agreeing on them it is impossible for us to have a productive conversation about probability theory.
- The probability of any event \(E\) in the sample space \(\Omega\) [\(E \subseteq \Omega\)] is between 0 and 1: \[ 0 \leq {P(E)} \leq 1.\]
- The probability that at least one of the elemental events in the sample space occurs is 1: \[{P(\Omega)}=1.\] This means that the sample space must contain at all possible outcomes.
- The probability of the union of two events occurring is given by: \[{P(E_1 \cup E_2)}={P(E_1)}+{P(E_2)}-{P(E_1 \cap E_2)}\]
6.3.4 The OR Rule
The last axiom of probability actually can be very useful in calculations, I call it the OR rule of probability. Let’s break it down in some more detail. \[{P(E_1 \cup E_2)}={P(E_1)}+{P(E_2)}-{P(E_1 \cap E_2)}\] This tells us that the probability of the event \(E_1\) OR the event \(E_2\) occurring is the sum of the probabilities that \(E_1\) and \(E_2\) occur minus the probability that both \(E_1\) and \(E_2\) occur.
Perhaps it is best to make sense of this using a simple example. Suppose we are rolling a six sided dice. Then the sample space \(\Omega=\{1,2,3,4,5,6\}\) and each outcome is equally likely. Let \(E_1=\{2,4,6\}\) be the event and even number is rolled and let \(E_2=\{1,2,3\}\) be the event that an number less than or equal to three is rolled. Then \({P(E_1\cup E_2))}={P(\{1,2,3,4,6\})}=5/6\) finding this directly. Now the OR rule tells us we could also find this as \({P(E_1)}+{P(E_2)}-{P(E_1 \cap E_2)}={P(\{2,4,6\})}+{P(\{1,2,3\})}-{P(\{2\})}=3/6+3/6-1/6=5/6\).
Why does this work? Notice that when we break up the set \(E_1 \cup E_2\) we end up counting the event that a two is rolled twice! It appears in both \(E_1\) and \(E_2\). Therefore, to correct for this we need to subtract off this double counting.
The OR rule is especially simple and useful when \(E_1\) and \(E_2\) have no overlap, i.e \(E_1 \cap E_2=\emptyset\). Sets with this property of no overlap are called disjointed sets. Then we have the following simple rule:
6.3.5 The AND Rule
We are now ready to discuss the powerful AND rule. This will allow us to find \({P(A \cap B)}\) easily under the special circumstances that the events \(A\) and \(B\) are ``independent’’.
We will give a mathematical definition for independence in the next section of the notes. For now we will use the intuitive definition that two events \(A\) and \(B\) are independent if the occurrence of \(A\) has no effect whatsoever on the likelihood of \(B\) occurring and vice-versa. For example, my hair color has nothing to do with the probability I am eaten by a shark. Rolls of a dice, spins of a roulette wheel and many other gambling events are independent events.
6.3.5.1 Exercise
- People vs Collins: In 1968 an old lady in Los Angeles, California was mugged and her purse was stolen. She didn’t get a good look at her assailants but the police did find one eye witness. Unfortunately, this witness didn’t get a good look at the mugger either. However, the witness did report seeing a black man with a beard/mustache running back to a yellow car with a blond haired white woman with her hair in a pony tail. This was very little to go on, however the police did find a couple which matched his description. Amazingly, using just this evidence they were brought to trial. At the trial a mathematics professor was brought in to testify for the prosecution. The professor presented the below table to the jury:
| Characteristic | Probability |
|---|---|
| Black man with beard | 1/10 |
| Man with mustache | 1/4 |
| White woman with pony tail | 1/10 |
| White woman with blonde hair | 1/3 |
| Yellow car | 1/10 |
| Interracial couple | 1/1000 |
The fact that this was presented by a math professor brings me great shame (for many reasons). Let’s examine the argument made by the professor.
- Using the AND rule what are the odds assuming these numbers are accurate in 1968 that a couple would match these all these characteristics?
- What is wrong with applying the AND rule to this data?
- If there were 60 million couples in the LA area at the time, about how many couples will match this description?
- What is the probability that the couple that was arrested actually committed the crime? (Given your calculations above)
This poor couple was convicted and it took years of appeals before the conviction was overturned. This is called the prosecutors fallacy. You will see another tragic case of this in your homework (Sally Clark Case).
6.3.6 The Complement Rule
One last rule to introduce for calculating probabilities. This is called the complement rule. The idea here is that sometimes it is easier to calculate the odds that an event does NOT happen, then to calculate the probability directly.
As an example if your doctor tells you that there is a 25% chance that you have a rare disorder based on your test results. Then you could also phrase this as a 75% chance you do NOT have the disorder. I would prefer the doctor tell me this way!
6.4 Conditional Probability and Independence
6.4.1 Introduction
Conditional probabilities allow us to include additional information into our calculation of probabilities. Let’s begin with some examples:This is much better odds of guessing the correct day. The notation \({P(B|M)}\) should be read The probability of \(B\) given \(M\). In the psychic problem B is the event of guessing my birthday correctly and \(M\) is the event that the month I was born in is December.
In practical situations we deal with this type of situation, where we wish to calculate the odds of something we have partial knowledge of. For example,
What is the probability your spouse is cheating on you, given the new information that you found strange text messages on their phone?
What is the probability of someone living past the age of 70? What about if you are given the added information that they smoke?
What is the probability of that you have the flu, given that you have a slight fever?
6.4.2 Mathematical Definition
We can get an idea for why this formula works by looking at a Venn diagram for conditional probability (Figure.~).
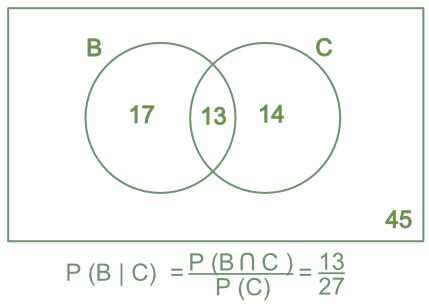
Figure 6.1: Venn Diagram of a conditional probability calculation. The numbers indicate the number of outcomes in each category. Knowledge that \(C\) has occurred limits the possibilities down to 27 possible outcomes, and means only 13=B intersect C of the outcomes in \(B\) are possible
6.4.2.1 Examples
- What is the probability of rolling a three with a dice, given that we know that an odd number was rolled?
Let \(\mathcal{O}=\{1,3,5\}\) be the event an odd number is rolled and \(\mathcal{T}=\{3\}\) the event a three is rolled. Then by our conditional probability formula we have
\[
{P(\mathcal{T}|\mathcal{O})}=\frac{{P(\mathcal{T} \cap \mathcal{O})}}{{P(\mathcal{O})}}=\frac{|\{3\} \cap \{1,3,5\} |}{| \{1,3,5\}|}=\frac{1}{3}
\]
Note that \({P(\mathcal{O}|\mathcal{T})}=\frac{{P(\mathcal{T} \cap \mathcal{O})}}{{P(\mathcal{T})}}=\frac{1/6}{1/6}=1\). This leads us to the important discovery:
Theorem 6.7 (Order Matters) In general for two events \(A\) and \(B\): \[{P(A|B)}\neq{P(B|A)}\] that is probability of A given B is not the same as the probability of B given A.As another example of this non-equality, let \(A\) be the event that someone is an professional basketball player and \(B\) be the event that someone is taller than 5.5 feet. Then the probability of B given A, \({P(B|A)}\), is quite large because most professional basketball players are much taller than 5.5. That is if someone is a professional basketball player you would be very surprised if they were shorter than 5.5 feet tall. However, if we consider the probability that someone in a professional basketball player given that they are taller then 5.5ft, that is \({P(A|B)}\), we can see it is quite small. This is because there are very few professional basketball players and many people taller than 5.5ft. Therefore, concluding every above average height person you meet is on the San Antonio Spurs is going to be wrong most of the time. The lesson here is that knowledge of \(A\) can tell us much more about \(B\) then vice versa.
- Say 5% of a particular emergency room patient arrive with pain in their lower right abdomen and must be rushed to surgery, and 1% of the people arriving have appendicitis and pain in their lower right abdomen. If a new patient comes with pain in their lower right abdomen what is the probability they have appendicitis? Let \(A\) be the event they have appendicitis, and \(P\) be the event they have abdominal pain. Then we want to compute the probability \[{{P(A|P)}=\frac{{P(A \cap P)}}{{P(P)}}}=\frac{0.01}{0.05}=\frac{1}{5}=20\%\]
Exercise 6.22 In 2016 the Cleveland Cavaliers had the following record in home and away games:
| Outcome | Home | Away |
|---|---|---|
| Wins | 31 | 20 |
| Losses | 10 | 21 |
6.4.3 Independence
Now that we have a knowledge of conditional probability we can return to the question of independence of random events.
Practically this means that the probability of \(A\) occurring is not changed whatsoever by the knowledge that \(B\) has occured. For example, the probability of me being struck by lightning is is no way effected by the color of my hair.
If two events are independent then using the definition of conditional probability gives: \[ {P(A)}={{P(A|B)}=\frac{{P(A \cap B)}}{{P(B)}}} \] \[ {P(A\cap B)}={P(A)} \times {P(B)} \]
This is called the AND rule of calculating probabilities because if \(A\) and \(B\) are independent events then the probability of \(A\) AND \(B\) occurring \({P(A \cap B)}\) is the product of the probabilities.
6.4.4 Multiplicative Rule
If \(A\) and \(B\) are dependent (that is not independent) then we can use the multiplicative rule of probabilities to find \({P(A \cap B)}\). This is a more general AND rule.Let \(W_1\) be the event the first sock is white and \(W_2\) the event the second sock is white. We want \[{P(W_1 \cap W_2)}={P(W_2|W_1)} {P(W_1)}, \] using the multiplicative rule for probabilties. Now, \({P(W_1)}=6/12=0.50\), but \({P(W_2|W_1)}=5/11\) because after drawing the first sock out we keep it. Therefore, their are only 11 socks left in the drawer, 5 of which are white. Therefore, we have \[ {P(W_1 \cap W_2)}={P(W_2|W_1)} {P(W_1)}=6/12 \times 5/11= 0.227 \] Notice that \({P(W_1 \cap W_2)} \neq {P(W_1)} \times {P(W_2)}=1/4\), this tells us that drawing the socks are not independent events. This is because we keep the first sock in our hand before drawing the second. This is called sampling without replacement and this can often break independence between events.
6.4.5 Law of Total Probability
The law of total probability allows us to use break down a complex probability calculation into a series of simpler calculations using conditional probabilities. To use the Law of Total Probability we need to form what is called a partition of our sample space.
The Venn diagram of a partition is shown in Fig~.
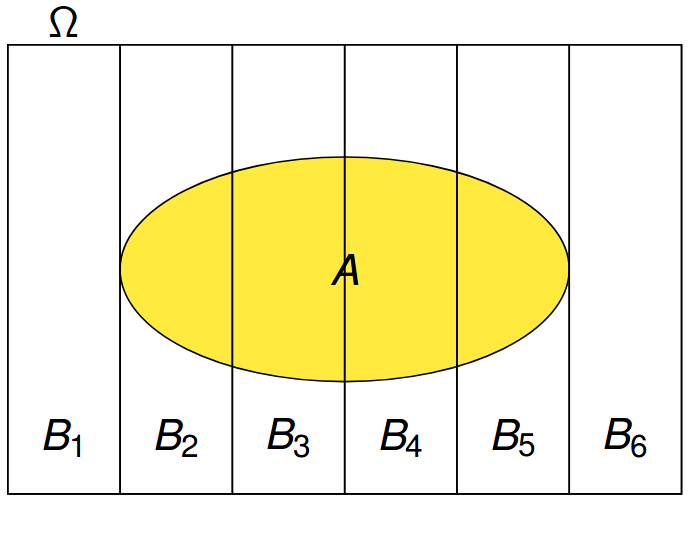
Figure 6.2: Here we partition the sample space into 6 disjoint components \(B_1, B_2, .... B_6\)
The law of total probability tells us we can compute the probability of an event by breaking it into a series of disjoint slices then adding up the contributions of these slices to get the total back. This will come in useful when the slices have probabilities which are easy to find.
Let \(A\) be the event that the first card is an Ace and \(A^c\) the event that the first card is not an ace. These two events are a partition of our sample space as the first card is either an Ace or not an Ace and it cannot be both. Therefore, we can use the Law of Total Probability to find the probability the second card is an Ace, call this event \(S\). We have that, \[ {P(S)}={P(S|A)} {P(A)}+{P(S|A^c)}{P(A^c)} \] We can find each of these probabilities easily:
\[ \begin{align} &{P(A)}=\frac{4}{52}=\text{Probability the first card is an Ace} \\ &{P(A^c)}=\frac{48}{52}=\text{Probability the first card not an Ace} \\ &{P(S|A)}=\frac{3}{51}=\text{Probability the second card is an Ace, when the first was an Ace} \\ &{P(S|A^c)}\frac{4}{51}=\text{Probability the second card is an Ace, when the first card isn not an Ace} \end{align} \]
Now plugging these back into our law of total probability
\[{P(S)}=\frac{3}{51}\times \frac{4}{52} + \frac{4}{51}\times \frac{48}{52} =\frac{4}{52} \]
Let \(S\) be the event the chicken makes you sick. Let \(M\) be the event the chicken came from Old MacDonalds Chicken Inc and \(SC\) be the event it came from Sick Chicken Inc. Since the chicken had to come from one of those two suppliers, and can not have come from both we have a partition of our sample space. Then the law of total probability tells us that: \[ {P(S)}={P(S|M)}{P(M)}+{P(S|SC)}{P(SC)}=0.05 \times 0.70 + 0.40 \times 0.30=0.155=15.5\% \]
6.5 Bayes Rule
From our knowledge of conditional probability we know that \[{P(D|M)}{P(M)}={P(M \cap D)}={P(M|D)}{P(D)}.\] From this observation we can get a rule for reversing a conditional probability order. This is called Bayes Law or Bayes Rule.
Notice I used the law of total probability to write \({P(D)}=\sum {P(D|M_i)}{P(M_i)}\). This is the most common way to use Bayes law.
You may have noticed I switched from using the notation A and B for events to using M and D for Bayes rule. This change was intentional as we can think of the M as the model and D as the data. In this way we may update our belief in a model (scientific theory, business conclusion) as we add additional data (D). In this way Bayes rule encompasses the scientific method by allowing us to measure the strength of evidence for a particular theory against the available evidence.
For example, lets suppose that I have a been handed a coin which was randomly chosen from a bag with contains 1/2 fair coins and 1/2 biased coins. The fair coins will come up heads 50% of the time. The biased coins will come up heads 55% of the time. I am trying to figure out which type of coin I have been handed.
To investigate this I will collect data by flipping the coin say 5 times and recording the outcomes. Let’s say I flip this coin 5 times and I find that it comes up heads all five times. Let F be the event the coin is fair and B the event it is biased. D represents the data we have collected (five heads).
We may use Bayes rule to calculate the probability \({P(F|D)}\): \[ {P(F|D)}=\frac{{P(D|F)}{P(F)}}{{P(D|F)}{P(F)}+{P(D|B)}{P(B)}} \]
We can fill in this data:
- \({P(D|F)}\) is the probability of observed the data given the model (fair coin) this is given by \((1/2)^5=1/32\).
- \({P(F)}\) this is the probability the coin we were handed is fair. Since we know the bag with the coins in it has a 50/50 mix of fair/biased coins we can say this equals \({P(F)}=0.50\), For the same reasons we have that \({P(B)}=0.50\)
- The only remaining entry to find is the \({P(D|B)}\) term. This is the probability we get 5 heads in a row using the
biased coin thus \({P(D|B)}=0.55^{10}\)
\[ {P(F|D)}=\frac{{P(D|F)}{P(F)}}{{P(D|F)}{P(F)}+{P(D|B)}{P(B)}}=\frac{0.50^5\times 0.50}{0.50^5 \times 0.50+0.55^5\times 0.50}=0.383=38.3\% \] Likewise we can find \({P(B|D)}\) as: \[ {P(B|D)}=\frac{{P(D|B)}{P(B)}}{{P(D|F)}{P(F)}+{P(D|B)}{P(B)}}=\frac{0.55^5\times 0.50}{0.50^5 \times 0.50+0.55^5\times 0.50}=0.617=61.7\% \] Given this data Bayes law tells us it is more likely that we have a biased coin. Notice that if we flipped the coin 10 times and found heads everytime then we would find:
\[ {P(B|D)}=\frac{{P(D|B)}{P(B)}}{{P(D|F)}{P(F)}+{P(D|B)}{P(B)}}=\frac{0.55^{10}\times 0.50}{0.50^{10} \times 0.50+0.55^{10}\times 0.50}=0.721=72.1\% \]
This should make sense the more heads we find in collecting our data the more likely it is that the coin is biased towards heads.
6.6 Homework
6.6.1 Concept Questions
- What is the Law of Sample Spaces and when does it apply?
- What is the condition for applying the OR rule of probabilities?
- What is the condition for applying the AND rule of probabilities?
- Is it true that \({P(A \cap B)} \leq {P(A)}\)?
- Is it true that \({P(A \cup B)} \geq {P(A)}\)?
- For conditional probabilities does \({P(A|B)}={P(B|A)}\)?
6.6.2 Practice Problems
- How many 7-place license plates are possible if the first two places are letters and the last 5 places are numbers?
- Twenty workers are assigned to 20 different jobs, how many different assignments are possible?
- How many ways can a wedding table of 5 people be selected from a wedding party of 12 people?
Two fair dice are thrown and let E be the event that the sum of the dice is odd and F be the event the sum is less than 6
- Define \(E\) and \(F\) and the sample space \(\Omega\).
- Are \(E\) and \(F\) disjoint sets?
- Find \({P(E)}\) and \({P(F)}\)
- Find \(E \cup F\) and \({P(E\cup F)}\)
- Find \({P(E \cap F)}\)
- Are \(E\) and \(F\) independent events?
6.6.3 Advanced Problems
Advertising Decisions: You are trying to decide how effective your product advertisements are. You find that 61% of your customers are on Facebook, and 32% are on Twitter with 16% on both Facebook and Twitter. If you decide to pay for advertising on both Facebook and twitter what percentage of customers do you expect to reach?
DNA Evidence: In a murder trial and expert witness is called to testify about DNA evidence found at the crime scene. They say that the probability of a person randomly matching the DNA fragment found at the crime scene is approximately 1 in a million. In the cross examination the defense attorney asks what the probability of a lab mistake is during the processing of the evidence (contamination, human error, etc), to which the expert witness replies about 5% of the time.
- If we are a juror, we are interested in the probability the DNA evidence linking the defendant to the crime scene is false. Lets call this event \(F\). Call the event that the defendant is unluckily enough to share the DNA sequence with the real killer \(R\), and call the event that the lab screwed up and the match is false \(L\). How can we express \(F\) in terms of \(R\) and \(L\)?
- Using the numbers given by the expert witness find \({P(F)}\) in this case.
- Is this beyond your reasonable doubt? How would you explain this to your fellow jurors who aren’t skilled in probability theory?
The Simpson Trial: During the O.J. Simpson trial the prosecution argued that the history of domestic abuse by O.J. towards his ex-wife Nicole Brown showed a pattern of escalating violence which culminated in her murder. To make the point the chief prosecutor famously used the line ``A slap is a prelude to homicide’’. Predictably, the defense argued this history of domestic abuse meant nothing. The defense used the following statistics to make their argument: over 4 million women were victims of domestic abuse in 1992 and only 1,432 of these were killed by their significant others. Therefore the probability, in 1992, that an abuser murders their spouse is less than \(1/2500\). Therefore, they argued that very few wife beaters actually go on to murder their wives.
- Write the defense’s statistic in terms of a conditional probability where \(M\) is the event that the women is murdered by their abuser, and \(A\) is the event that they were previously abused.
- What key piece of information is the defense conveniently forgetting to condition on? Hint: Is it relevant to consider the probability that O.J. will murder Nicole at some future date?
- If I told you that 90% of the time when an abused women is murdered, the murderer was the abuser (this is true). How would you respond to the defenses argument?
Sally Clark Case: Sally Clark was a women in England who in 1999 was convicted of killing her two children. The first child’s untimely death was put down to Sudden Infant Death Syndrome (SIDS). However, when two years later another seemingly healthy child suddenly died, Sally was accused of murdering the two children. The thrust of the prosecutions argument hinged on the fact that SIDS, thankfully, is relatively rare. The odds of a randomly chosen baby, dying from SIDS is about 3 in 5000.
- If the two deaths are independent then what is the probability of having two children who die of SIDS?
- If 130 million babies are born worldwide each year, about how many will die from SIDS using the 3:5000 odds?
- If 50,000 mothers have another child after having a child die of SIDS about how many will have a second child die from SIDS assuming the two deaths are independent?
- Using you answer from part(c) how would you defend Sally in court?
If two events \(A\) and \(B\) are disjoint (i.e. \(A \cap B=\emptyset\)) does this mean they are independent? If not give an example of a case where this fails. Hint: Consider \(A\) and \(A^c\).