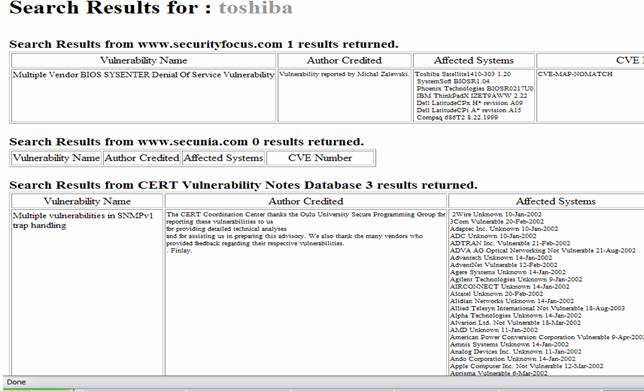
Figure 1: Example search results from our database.
| Automatically Building an Information-Security Vulnerability Database |
Extended Abstract
Our goal was to collect data from the myriad computer vulnerability notices that exist on the World Wide Web and to mine it for interesting information and patterns. Surprisingly, no single database currently brings together all the various kinds of data from the vulnerability sites. Of particular interest to us was author and discoverer information since this provides valuable information about who is active in information security and occasionally might indicate the authors of exploits; current databases do not connect this to other relevant information. We found that the searchable parameters of the existing vulnerability databases were limited and inconsistent. Consequently, it is very difficult to get complete information about computer vulnerabilities by searching Web sites.
Our approach was to bring together this information into a composite database. We did automated data collection from the existing Web vulnerability databases by creating Web bots that traversed Web sites and retrieved selected information from them, then imported the collected Web data into a relational database. A browser provides Web-based access to this database. [1] and [2] shows how such information can be used to build models of attacks in the form of graphs, trees, and finite-state machines, and thereby develop methods for system protection.
We first wanted to use the Carnegie-Mellon US-CERT database (www.kb.cert.org/vuls) of 22,716 vulnerabilities from 1995. However, it is not downloadable online. So we took records from the Common Vulnerability and Exposure (CVE) database (cve.mitre.org) with 15,000 entries, 11,000 entries from Secunia (www.secunia.com), 1,500 entries from US-CERT Vulnerability Notes Database (www.kb.cert.org/vuls) and 15,000 from SecurityFocus, more a newsgroup reporting vulnerabilities (www.securityfocus.com/bid). The National Vulnerability Database (NVD) (nvd.nist.gov) contained mostly the same information as the CVE database in an XML format, and the Open Source Vulnerabilities Database (www.osvdb.org) appeared to duplicate most of the other information, so we did not use their data. Each database had its weaknesses. The US-CERT database could not be downloaded as a whole, only in small groups of records; the CVE database did not list discoverers or reporters of vulnerabilities; the Secunia and SecurityFocus databases did not contain data on all vulnerability alerts and candidates, and their vulnerability descriptions were often cryptic.
Using ideas from [3], we created bots that collected information from the Web sources. These used crafted links to access forms pages and then processed the results in Java. Only the CVE database provided an easy means to download their database. The US-CERT Vulnerability Notes Database does not allow bots to search the database except by vulnerability number, and this appears randomly assigned from 1000 to 999999; so we manually grabbed the 54 pages of information containing vulnerability identifiers and iteratively searched for those with a bot. The Secunia database could be indexed by entry number ranging from 1 to 13000 with some omissions, so we just retrieved all 13000, getting blank pages for the omissions; however, some entries had no numbers and could not be found this way. Finally, we retrieved the SecurityFocus database pages in the same manner as Secunia, again getting some blank pages for nonexistent numbers.
For each of these databases we analyzed the formats to develop ways to extract and organize the data on the page. We created a relational database using PostgreSQL, using character fields for each of the pieces of information extracted from the websites. Each site had a separate table for its data of 4000-15000 records. Text had to be cleaned up in a number of ways before entering it into this database, including conversion from HTML to strings, from strings to SQL char fields, from SQL char fields to strings, and from strings to HTML. There were also many small problems with non-English, Unicode, and punctuation characters, as well as the handling of a few large text entries.
We created a Java servlet for free-text keyword search on the database. It can search on vulnerability name, author, CVE number, or affected system. These keyword searches are then coded into SQL and passed to the database. Selections, projections, and joins are made on our tables as necessary to produce the results. Currently, results are returned as tables, one for each of the selected source sites (Figure 1). Posing questions, like what percentage of vulnerability notices have a CVE number associated with them, involved some challenges in structuring the proper queries in SQL. These were fairly large tables and performing queries with join operations, such as finding data unique to one table, were prohibitively slow on a laptop computer. The CVE vulnerability numbers were quite helpful, since a vulnerability was often described quite differently by each organization.
In seeking author or credit information, we found many entries of the Secunia site to state "no credit." Redesigning the Secunia bot to recursively search referenced advisories from those that provided no credit information reduced the number of "no credit" items from 40% to 15%. Interestingly, while the total number of vulnerabilities has been increasing since 1999, Mitre (the keeper of the CVE database) has labeled fewer candidate vulnerabilities (Figure 2).
Another discovery was that the security-company data collection was not capturing the volume of vulnerabilities reported by the US-CERT (Figure 3). Also of note is that individuals and private firms are critical to discovering vulnerabilities, since in both the Secunia and the SecurityFocus databases over 70% of the vulnerabilities were not found by the manufacturer of the software or hardware.
Figure 1: Example search results from our database.
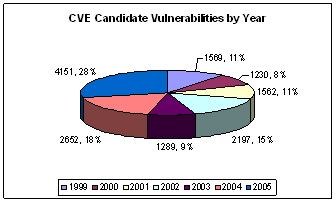
Figure 2: Vulnerabilities submitted to Mitre’s CVE database per year.
Though not complete, this project has achieved most of its goals in collecting, storing, and accessing the computer-vulnerability database information from the Web. Even now, our system can provide some interesting data not easily gleaned from the Web. Comparisons between the commercial and the government sites will also prove interesting. Further development of the project would yield some answers about the timeliness of vendors in issuing resolution to problems, trends in systems vulnerabilities in contrast to competitors, identifying trends in authoring and submission of vulnerabilities, and measure how well the CVE naming convention for vulnerabilities is being used and applied.
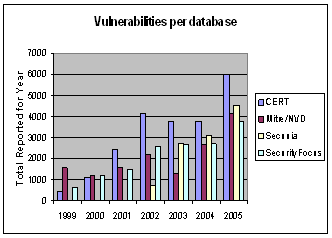
Figure 3: Vulnerability trends for our source databases.
[1] Steffan, J., and Schumacher, M., "Collaborative Attack Modeling," Proc. of Symposium on Applied Computing, Madrid, Spain, 253-259, March 2002.
[2] Iyer, R., Chen, S., Xu, J., and Kalbarczyk, Z., "Security Vulnerabilities - from Data Analysis to Protection Mechanisms," Proc. Ninth IEEE Workshop on Object-Oriented Real-Time Dependable Systems, October 2003.
[3] Heaton, J., Programming Spiders, Bots, and Aggregators in Java, San Francisco: Cybex, 2002.
This paper appeared in the 7th IEEE Workshop on Information Assurance, West Point, NY, June 2006.
Manuscript received on May 3, 2006. This work was supported in part by NSF under the Cyber Trust Program. Contact the authors at Code CS/Rp, 833 Dyer Road, U.S. Naval Postgraduate School, Monterey, CA 93943. Email: adarmold, bmhyla, and ncrowe at nps.edu. Opinions expressed are those of the authors and do not represent the U.S. Government.