Finding Contextual Clues to Malware
Using a Large Corpus
Neil C. Rowe
Dept. of Computer Science
U.S. Naval Postgraduate School
Monterey, California, USA
ncrowe@nps.edu
Abstract - Identification of malware is a critical
problem in computer security. Many signature-identification,
behavior-recognition, and reputation-based tools are available for host-based
detection. However, so many files are present on systems today that checking
all files is time-consuming, and better methods are needed to suggest which
files are of highest priority to check in partial scans. This work developed
and tested local contextual clues to malware in the metadata of file systems on
an international corpus of 248 million files on 3961 drives. 398,949 hash
values of malware were found in this corpus using five methods, and 3,681,211
hash values of non-malware were chosen for comparison using three methods.
Malware identification rates were compared for the fifteen combinations and
were cross-correlated for different types of drives and file types. Results
showed that different malware identification methods find significantly
different things. Then the strength of particular local clues in file metadata
(directory and file names, sizes, times, and hash values) was assessed and
results were compared for the fifteen combinations. Some classic clues (e.g.
rare file extensions and deletion status) were confirmed and others were not
(e.g. double extensions and occurrence in the operating system). With this
data, a program was implemented to estimate the likelihood that a given file
was malware based solely on its metadata context. With three random subsets of
our corpus, our methods gave 5.1 times better precision (fraction of malware in
files identified as malware) with 70% better recall (fraction of malware
detected) than the approach of inspecting executables alone. They also ran
significantly faster than signature checking, and can be used before other
kinds of malware analysis.
This paper appeared in the Proc. of Third Intl. Workshop on
Security and Forensics in Communications Systems, Larnaca, Cyprus, July 2015.
Keywords - malware; context; clues; testing; hashes
I. Introduction
Identification of malware files and packets is a key task in
information security. Most methods rely on signature checking [1, 2, 3] or
behavioral analysis [4, 5]. The major disadvantages of signature checking are
that clever malware authors can vary their code to have new signatures, and
totally new malware cannot be recognized. The major disadvantages of
behavioral observation are that clever malware authors can camouflage behavior
so it cannot be recognized, and the malware may already have done damage by the
time it is recognized. This suggests that methods for identifying the
likelihood that malware will occur in a given context could be useful.
Internet packets provide some context such as protocol and source address to
permit blacklisting, and some anti-malware products attempt to assign
"reputation" to unknown files by this origin information or by frequency of
occurrence [6]. But this requires knowledge that is not always available and,
as advertisers know, it is not hard to buy a reputation.
Less has been explored with the context of files in file systems.
Storage capacities are so large on computer systems today that it slows
operating systems to do repeated full scans for signatures or behavior (it
typically requires four hours for signature checking on an older workstation).
It is helpful to set priorities and check the most suspicious files first.
Many systems have "quick scans" that claim to check just the most critical
files for malware, e.g. [7], but their criteria have rarely been subjected to
careful testing.
Contextual clues that could
be useful are measures of atypicality or deception associated with the file.
Atypicality could be in the contents, locations, or times compared to other
similar files in a large corpus. Deception could be obfuscation such as odd
characters in the path name or file contents inconsistent with the file
extension. Then any files matching the clues could be subjected to detailed
signature and behavioral analysis. Such clues could indicate new malware whose
signatures are as yet unknown. Surprisingly little work has been done on this
idea with host-based data.
II. Obtaining
Malware for Testing
A corpus-based big-data
approach appears to be a good way to obtain contextual clues. A broad and
realistic corpus is central to this research since it allows evaluation of the
success of malware clues on data that users are likely to encounter, not just
theoretical threats [8]. It is also important to examine realistic files in
realistic contexts because the two go together; while there are a number of
malware collections, they generally fail to provide the context in which the
files were found because of privacy and data-size concerns. Also, malware
collections generally fail to provide frequency information for their malware,
information necessary for cost-benefit analysis of threat clues. The
pioneering work of [9] suggests that useful statistics can be obtained from
large samples of ordinary files. Malware is relatively rare, so samples are
needed of millions of files to see patterns. Diversity of the machines
sampled is also important for useful results [10]. Corpus-based approaches are
popular and powerful in many areas of computer science, but are relatively rare
for information-security problems and deserve to be explored.
The experiments reported
here used a corpus of 248,829,846 files on 3,961 drives including data from
about 83 million files of the Real Data Corpus [11], as well as 161 million
files at our school obtained by inventorying several hundred classroom and
laboratory computer drives (having no private user files), 3 million files
obtained from a research sponsor, and 1 million files from our personal
computers. The Real Data Corpus consists of drives purchased as used equipment
in 36 countries over the last 20 years; the school computers were accessed in
2014. While there are more files from our school than any other source, their
rate of malware was low, so they did not bias the positive clues very much.
The entire corpus came from computers and devices used for normal purposes;
none had been deliberately infected with malware, and none had been used as
honeypots, both of which could create atypical malware patterns. Compressed
archives (zip, rar, cab, gzip, etc.) were expanded when possible and analysis
done on their subfiles. The following methods were used to identify malware:
· Files
in our corpus whose SHA-1 hash values were tagged as "high threat" (level 10)
and "low threat" (level 5) in the database of the Bit9 Forensic Service
(www.bit9.com). This analysis appears to be signature-based.
· Files
in our corpus whose SHA-1 hash values were tagged as one of the "vulnerable
software" categories in Bit9 (levels 1, 2, 3, and 4). These are not malware
but provided a necessary comparison to the other sources.
· Files
in our corpus whose computed hash values matched those of malicious software in
the Open Malware corpus (oc.gtisc.gatech.edu:8080)
of about 3 million files.
· Files in our corpus whose computed
hash values matched those of malicious software in the VirusShare database
(virusshare.com) of about 18 million files, after mapping its MD5 hash values
to SHA-1.
· Files
identified as threats by Symantec antivirus software
(www.symantec.com/endpoint-protection) in a sample of files extracted from the
corpus. The sample was downloaded to a home computer with the antivirus
software installed, and every file that Symantec complained about was
recorded. Only a sample could be tested because the corpus is too big to store
online and extraction of files is time-consuming. The sample included about
300,000 random files plus 30,000 embedded files of type zip, gzip, cab, 7z, and
bz2 because of their higher fraction of malware. Also included were 7,331
files from the Open Malware corpus whose hashcodes matched those of our corpus
files, of which only 721 were flagged as malicious by Symantec.
· Files
identified as threats by ClamAV open-source antivirus software (www.clamav.net)
in the same sample of files tested by Symantec.
It is important to
note that these malware methods do not just examine executables. They
identified 26,111 executables as malicious but also 41,540 graphics files, 29,378
source files, 24,498 Web files, 18,022 operating-system files, and 14.254 files
with no extension. Executables were only 6.5% of the files identified as
malware. All the methods found significant numbers of non-executables.
All these methods
except Bit9 identified the empty file as malicious. This is unreasonable, as
are any files of size five bytes or less being malicious, since there is no
room to put malware in them (even malicious URLs need more than 5 bytes) and
the odds of an accidental coincidence with a legitimate file in our 108,013
files 1-5 bytes in length are high. So we excluded all files five bytes or
less, which covered 64 distinct hash values. The result was 398,949 distinct
hash values for 1,772,961 allegedly malicious files in our corpus according to
at least one malware method.
We also collected
nonmalicious hash values ("whitelists") to compare the malicious files
against. We tested four sets:
· The
set of files explicitly whitelisted by Bit9 on our corpus, those it marked as
safe or type 0, minus those identified as malware by any of our five methods.
· The
June 2014 version of the National Software Reference Library Reference Data Set
(NSRL RDS, www.nsrl.nist.gov)
giving commonly seen software hash values, mostly those of software and its
support files, minus those identified as malware by any of our five methods. Its
documentation explicitly states it does not try to exclude malware. However,
its methodology of purchasing and installing recognized software does tend to
exclude malware, as was later confirmed.
· A
random sample of our corpus minus those identified as malware by any of our
five methods. Unlike the first two, this set included a significant number of
user files. It likely included unrecognized malware but the number of such
files is likely too low to influence analysis results, judging by the rate of infection
of malware which we did identify.
· A
random sample of the union of the above whitelist sets. A sample was necessary
because from the above three sets we had 78 times more whitelist data than
blacklist data.
Hash values were
excluded from the malware lists if they appeared in any of the whitelist sets,
and hash values were excluded from the whitelist sets if they appeared in any
of the malware sets; the reasoning was that anything with contradictory
evidence represents a poor example for either category. This was termed
"cleaning" the hash-value sets. It is however not perfect in eliminating
malware since undiscovered malware could still be present in the whitelist sets.
Altogether we extracted 3,316,443 distinct hash values for both the malware and
whitelist sets, which matched 128 million of the 249 million files in our
corpus.
Table I shows the
counts of intersections between these hash sets. The first number represents
the counts on the raw hashcodes obtained, and the second number represents the
counts after cleaning. As mentioned, Bit9 was run on the
Table
I. Intersection counts of whitelist and blacklist hash sets for files; first
number is before cleaning and second number is after. BW = Bit9 whitelist of
our corpus, NW = NSRL matches to our corpus as a whitelist, RW = random corpus
whitelist, BT = Bit9 identified threats in our corpus, BV = Bit9 identified
vulnerabilities in our corpus, OM = Open Malware corpus in our corpus, VS =
VirusShare corpus in our corpus, SM = Symantec Endpoint Protection on a sample
of our coprus, CA = ClamAv Antivirus on a sample of our corpus.
|
|
BW
|
NW
|
RW
|
BT
|
BV
|
OM
|
VS
|
SM
|
CA
|
|
BW
|
707917/
705004
|
192121/
192090
|
57301/
57301
|
22/0
|
0/0
|
5160/0
|
929/0
|
94/0
|
298/0
|
|
NW
|
192121/
192090
|
2167233/
2167048
|
140841/
140834
|
591/0
|
4554/0
|
2582/0
|
4093/0
|
6/0
|
43/0
|
|
RW
|
57301/
57301
|
140841/
140834
|
809168/
809158
|
0/0
|
512/0
|
0/0
|
2363/0
|
5/0
|
0/0
|
|
BT
|
22/0
|
591/0
|
0/0
|
239284/238704
|
0/0
|
418/409
|
28/28
|
289/280
|
400/393
|
|
BV
|
0/0
|
4554/0
|
512/0
|
0/0
|
10062/5462
|
113/25
|
6/0
|
0/0
|
1/0
|
|
OM
|
5160/0
|
2582/0
|
0/0
|
418/409
|
113/25
|
7338/4786
|
187/121
|
745/719
|
1002/981
|
|
VS
|
929/0
|
4093/0
|
2363/0
|
28/28
|
6/0
|
187/121
|
151706/145449
|
19/19
|
33/32
|
|
SM
|
94/0
|
6/0
|
5/0
|
289/280
|
0/0
|
745/719
|
19/19
|
1434/1401
|
880/877
|
|
CA
|
298/0
|
43/0
|
0/0
|
400/393
|
1/0
|
1002/981
|
32/32
|
880/877
|
2598/2555
|
entire corpus, but Symantec and
ClamAV were run on only a sample. Note these counts are of hash values, not
files, and the number of times a hash value occurred could vary significantly;
one hash value for an autorun.inf file occurred 14,401 times in the corpus, and
195 hash values occurred at least 100 times.
As a quick check of
whether the unique malware identified by each malware hash set was valid, the full
paths in our corpus were examined for a sample of hash values. No obvious mistakes
were apparent in what was identified, though VirusShare found a good number of
suspicious files under Agilent, Cygwin, and various mobile-device applications
that could be arguable.
The most common
malware in terms of number of drives infected were an UNWISE.EXE spyware
variant with SHA-1 hash value 3C4735750C99C63E6861170A8C459A608 594211 (579
drives), an external_extensions.json settings file (401 drives), a CPLUt164.exe
driver variant (291 drives), a pndx5016.exe Windows operating-system executable
(290 drives), a googletalk.exe variant (267 drives), a yupdater.exe variant
(246 drives), an alcwzrd.exe driver variant (242 drives), an alcmtr.exe variant
(241 drives), a SoundMan.exe variant (236 occurrences), and a msfeedssync.exe
variant (214 drives). 7908 distinct malware hashcodes occurred on at least
ten drives. This suggests that it is important not to exclude files during a
malware investigation that occur frequently (a key factor in file "reputation")
since some infections are widespread.
Overall, there was
surprisingly little overlap between malicious hash values identified by the malware
methods. Of the 398,949 unique malware hash values found by all methods, only
1,025 occurred in two or more hash sets. Modeling this as random sampling with
replacement suggests that the total number of malware instances in our corpus
should be at least 30 times the number found, or around 10 million hash
values.
Consistent with the
results of [12] on a smaller and less representative set of files, our results
support the conclusion that the five malware-identification methods are looking
for different kinds of things. Note that the hypothesis that some malware
methods include files that merely contain vulnerabilities rather than exploits
is not supported by the data in the BV (Bit9 vulnerability) column, since there
was very little overlap between Bit9’s vulnerable set and the malicious hash
sets. Note also while some malware may be more dangerous than others, it is
difficult a priori to identify the most dangerous since malware can spread from
many types of files to more dangerous locations, so we count everything
identified as malware equally.
The
drives came from several sources, so it is useful to break down malware
occurrence by type of drive. The categories were those from our school, those
from the Real Data Corpus, those from mobile devices including those in the
Real Data Corpus, those from Microsoft Windows systems, and those embedded in
archive files. Table II shows comparative malware identification rates for
different types of drives. Two numbers are given in each entry: the fraction
of hash values identified as malicious in all the hash values observed for the
data source, and the fraction of files identified as having malicious hash
values of all files of the data source. Infection rates were seen to be on the
order of 1 in 10,000 for the malware-identification methods with the exception
of the VirusShare data and mobile-device files: VirusShare identified long
lists of files in mobile applications as malicious, which seems unlikely.
III. Evaluating
Contextual Clues to Malware
A variety of static local contextual
clues to malware files were tested. Some are based on our previous work in
identifying generally suspicious files, and some are new. The clues were:
· File
name
· File
size
· Depth
(level) of the file in the directory hierarchy
· Whether
file was deleted on the drive on which it occurs
· File
extension
· First
two directories in file path (top-level directories, ignoring computer name if
given)
Table ii. Rates of malware
occurrence in subsets of our corpus, measured as fraction of distinct hashcodes
whose hash value matched a malware hash value (first number) and fraction of
files that did (second number).
|
|
Bit9 threats
in our corpus
|
Bit9 identified
vulnerable in
our corpus
|
Open Malware
corpus in
our corpus
|
VirusShare
corpus in
our corpus
|
Symantec Endpoint
Protection on
corpus sample
|
ClamAV
Antivirus on corpus sample
|
|
School
drives
|
.000000,
.000000
|
.000099,
.000004
|
.000092,
.000070
|
.000047,
.000020
|
.000000,
.000000
|
.000009,
.000010
|
|
Real Data
Corpus
|
.000049,
.000186
|
.000249,
.000481
|
.000200,
.000741
|
.005296,
.002696
|
.000057,
.000188
|
.000114,
.000205
|
|
Mobile
drives
|
.000052,
.000105
|
.000000,
.000000
|
.000061,
.000152
|
.326605,
.210274
|
.000038,
.000103
|
.000052,
.000124
|
|
Microsoft
Windows
drives
|
.000039,
.000136
|
.000191,
.000167
|
.000174,
.000338
|
.000147,
.000083
|
.000045,
.000078
|
.000085,
.000132
|
|
Embedded
files
|
.000083,
.000039
|
.000033,
.000012
|
.000482,
.003000
|
.000138,
.000084
|
.000334,
.000678
|
.000892,
.000570
|
|
All drives
|
.000139,
.000141
|
.000166,
.000160
|
.000156,
.000340
|
.004741,
.001597
|
.000043,
.000083
|
.000083,
.000141
|
· Last
directory in file path (immediate directory containing the file)
· Class
out of 45 of file extension, using our taxonomy of 11,381 extensions
· Class
out of 12 of first two directories in file path, using our taxonomy of 3,662
top-level directories
· Class
out of 21 of last directory in file path, using our taxonomy of 8,909 immediate
directories
· Whether
the file is a registry file (suggested by [13])
· Whether
the creation time was atypical for the file’s directory, defined as not being
within a minute in which at least 50 files in the directory were created.
Last-modification times were not used because they often are times at the
software vendor, and last-access times were not used because many normal
directories have a few files that are accessed frequently.
· Whether
there were at least 10 different file names for the file’s hash value (which
suggests concealment attempts)
· Whether
the hash value is rare (defined as occurring only once)
· Whether
the file extension was compatible with its header and tail (magic-number)
classification
· Whether
the file extension is rare (defined as occurring only once)
· Whether
the file extension is known to be used for encryption (270 such extensions were
identified)
· Whether
the file extension is listed by www.file-extensions.org under the category
"dangerous and malicious" and does not have primarily legitimate uses like
"dll", "exe", and "chm"
· Whether
the file extension is double and the last part is not a conventionally used
double extension. The conventionally used ones we assumed were "mui",
"manifest", "lnk", "url", "log", "bak", "backup", "copy", "new", "orig",
"last", "sav", "save", "sorted", "mno", ‘resx", "prepare", "install_backup",
"mdmp", "config", "dll", "blf", "doc", "obj", "dmp", and "?".
· Whether
a double file extension conceals an executable
· Whether
the file extension is 10 characters or longer
· Whether
there were excessive punctuation characters: either one at the front of a
directory name other than "$" or "~", five or more punctuation characters in
the path, or punctuation characters in more than 10% of the path
· Whether
there was a clear misspelling in the path words, comparing to our large
multilingual dictionary including computer terms and many compound words. The
proposed misspelled word must occur 20 times or fewer times than a word in our
dictionary.
· Whether
the file extension forms a word with the filename but the filename alone is not
a word, e.g. "installation" (we saw this trick in some malware)
· Whether
there was a repeated pattern of 3-8 characters occurring at least three times
in the path characters (we saw this trick to create new file names in some
malware)
· Whether
the file name before the extension was numeric
· Whether
the file name before the extension was the letter "A" followed by a number
· Whether
the file name before the extension was hexadecimal rendered in digits and
letters
· Creation
time
· Modification
time
· Access
time
The malicious file sets were
compared to the nonmalicious file sets in regard to each of these clues. We
measured the significance of the clue by the number of standard deviations
greater than its rate of occurrence predicted by a binomial distribution. This
significance value is positive for positive clues and negative for negative
clues. Following standard
Table
III. Comparative significance of miscellaneous clues in identifying malware
files.
|
Malware set
|
Bit9
|
Open Malware
|
VirusShare
|
Symantec
|
ClamAV
|
|
Total count in corpus identified as malicious
|
35,202/
1,201
|
763,199/
7,331
|
1,006,412/
151,621
|
11,085/
626
|
25,972/
1,662
|
|
Total count in corpus identified as nonmalicious
|
12,094,989
/303,332
|
12,094,989
/303,332
|
12,094,989
/303,332
|
12,094,989
/303,332
|
12,094,989
/303,332
|
|
File size 0 or 1
|
-1.3/-0.3
|
-6.1/-0.7
|
1750/-0.9
|
-0.7/-0.2
|
-1.1/-0.3
|
|
Rounded log file size = 5
|
-8.5/-5.5
|
-223/-19.5
|
129/112
|
-27.7/-5.2
|
-9.6/-7.1
|
|
Rounded log file size = 10
|
-44.8/9.3
|
287/22.5
|
-187/-9.0
|
-33.6/-6.5
|
-36.2/-3.1
|
|
Rounded log file size = 15
|
-11.2/2.5
|
-33.9/23.4
|
-28.1/16.8
|
10.0/4.6
|
35.0/16.9
|
|
Level = 1
|
121.0/26.2
|
-46.6/9.7
|
-77.6/-47.1
|
-3.6/-2.4
|
124/14.7
|
|
Level = 5
|
-37.9/2.5
|
-65.7/7.4
|
5.2/-85.2
|
-20.7/-5.3
|
-29.8/5.5
|
|
Level = 10
|
-39.4/-6.6
|
-182/-15.8
|
-22.8/-8.2
|
11.0/-1.2
|
-17.7/-8.0
|
|
Level = 15
|
-23.8/-2.3
|
-110/-5.3
|
-99.2/-24.5
|
-13.4/-1.6
|
-17.5/-2.7
|
|
Deleted file
|
130.0/4.2
|
-213/3.1
|
595/1159
|
17.0/-1.4
|
115/10.6
|
|
Extension/ libmagic
incompatible
|
-116.5/6.4
|
-108.4/-4.1
|
-161/-60.0
|
-5.3/9.1
|
-2.6/6.6
|
|
Odd creation time
|
88.8/17.7
|
-79.0/9.1
|
-73.1/-46.1
|
-6.9/-2.0
|
4.3/13.2
|
|
Rare hash value
|
-0.3/na
|
2.1/na
|
-1.6/na
|
-0.2/na
|
-0.3/na
|
|
Rare
extension
|
996/2151
|
75.6/583
|
175/-24.4
|
3068/2874
|
1782/3287
|
|
Double extension
|
-25.1/-1.6
|
-119/-6.2
|
-77.1/-17.0
|
-5.9/12.8
|
-19.5/5.3
|
|
Long extension
|
-1.9/-0.9
|
-10.4/-1.5
|
17.1/8.0
|
-1.3/-0.7
|
-1.5/-0.2
|
|
Encryption extension
|
-8.5/-1.9
|
28.8/-4.2
|
-41.2/-17.6
|
-4.4/-0.6
|
-7.3/-2.2
|
|
Odd characters in path
|
-10.4/6.4
|
-90.1/7.2
|
-32.8/29.0
|
-26.5/-3.6
|
-38.2/-0.6
|
|
Repeated pattern in path
|
1.7/-0.4
|
-12.3/0.8
|
-8.5/16.4
|
-1.2/-0.3
|
13.3/75.5
|
|
Misspelling in path
|
-6.5/-1.2
|
-30.4/-1.2
|
-354/-11.9
|
-0.4/-0.8
|
-2.6/0.1
|
practice, we ignored clues with
significance values between -3.0 and +3.0. But as with other bursty digital
data such as network traffic, significance values well in excess of this were
frequently observed.
We calculated
significance in two ways, for number of malicious files and number of distinct
malicious hash values. The significance was often quite different for each;
for instance, we saw whole directories of files with names of popular games but
with the same malicious hash value. Significance in terms of number of files
is important in addressing the most common threats, and significance in terms
of number of distinct hash values is important in addressing novel or
recently-appearing threats. An information-security manager will likely act,
consciously or not, according to a weighted average of the two significance
factors since people when faced with two important numerical objectives tend
take a weighted average.
Tables III and IV
show the comparative results for the clues on the sets of malware, using in
each case as whitelist the random-sample consensus mentioned above. After the
first two rows of Table III, numbers are significance values measured in
standard deviations. The first number in each row is for all files matching
the malicious hash values, and the second number after the slash is for a
single randomly chosen representative of each hash value.
We only show
results for clues that demonstrated significance according to at least one
malicious hash set. For instance, clues related to the recency of creation,
access, and modification times provided no significant help at all, and no
registry files in our corpus matched any of the malicious hashcodes (apparently
there are far too many variations on registry files).
Table IV uses the
file-type classification based on file extension that was mentioned above.
Again the table only shows file types which showed strength in predicting
malware for at least one set of malicious hash values, which excluded some
common types such as graphics, temporaries, Web pages, documents, spreadsheets,
audio, logs, configuration files, and game-related files.
As for more detail
of the malware rates as a function of file size and file level, the logarithm
of one plus the file size showed peaks for 3-5 and again at 12-15 (the peak at
19 is based on too little data to be significant), and the file directory level
showed a significant peak for 7-9 (meaning paths consisting of 6-8 directories
plus a file name). (One was added to the file size to avoid a logarithm of
zero for the many zero-sized files.) Creation times are probably the best
measure of trends, and malware rates were clearly increasing in recent years,
though there is significant yearly variation. Peaks in 1980 and 1985 probably
represent default times.
It can be seen there is considerable disagreement between the
malware methods as to the good clues. Overall the best clues were file size,
files at top level of the directory structure, deleted files, rare hash values (consistent with reputation-
Table IV. Comparative significance of important
positive file-type clues in identifying malware files. In left column,
E=extension, T=top-level directory, and I=immediate directory of a file.
|
Malware set
|
Bit9
|
Open Malware
|
VirusShare
|
Symantec
|
ClamAV
|
|
E: None
|
-78.5/-10.5
|
-355/-27.5
|
226/-17.9
|
-42.9/-8.2
|
-67.5/-12.8
|
|
E: Photograph
|
-15.8/-5.3
|
-100/-14.8
|
9.8/110
|
-4.3/-3.1
|
-18.9/-4.6
|
|
E: Link
|
-5.9/4.8
|
-36.5/-1.8
|
-24.9/-15.9
|
-4.1/-1.0
|
-6.5/-1.1
|
|
E: Video
|
-8.5/-2.2
|
-16.8/-5.0
|
-28.5/-12.6
|
-4.7/-1.6
|
-7.2/-2.5
|
|
E: Executable
|
134/54.5
|
1979/162
|
-199/-166
|
158/18.2
|
26.6/25.3
|
|
E: Drive image
|
-3.6/-1.1
|
-16.2/-2.3
|
25.2/-8.1
|
-2.0/-0.8
|
-3.1/-1.3
|
|
E: Query
|
-12.5/-0.9
|
-58.1/-2.3
|
-24.4/20.8
|
-7.0/-0.7
|
-10.7/-1.1
|
|
E: Installation
|
758.1/6.4
|
-70.9/-5.0
|
-125/-43.8
|
-12.4/-2.2
|
702/-0.4
|
|
E: Networking
|
-5.0/-0.8
|
-22.5/-0.9
|
-3.7/-8.5
|
-2.9/-0.6
|
-4.4/-0.9
|
|
E: Hardware
|
-0.9/-0.4
|
595/1.8
|
-26.1/-14.0
|
-2.8/-0.9
|
-4.3/-1.5
|
|
E: Engineering
|
-13.8/-2.5
|
-64.2/-6.2
|
-64.2/-27.0
|
-7.7/-1.8
|
-11.8/-3.0
|
|
E: Miscellaneous
|
-3.0/-1.5
|
-10.2/-1.1
|
48.9/19.0
|
-2.0/-1.1
|
4.8/2.1
|
|
T: Root
|
51.8/18.3
|
-75.9/6.8
|
45.5/25.2
|
-60.4/-0.1
|
50.2/6.8
|
|
T: Hardware
|
115.1/-2.3
|
22.2/3.0
|
125/47.9
|
47.8/11.3
|
21.9/42.4
|
|
T: Temporaries
|
20.7/2.6
|
-219/8.1
|
-279/-121
|
33.3/14.4
|
-25.6/-2.3
|
|
T: Games
|
57.5/-2.5
|
-60.4/3.5
|
-27.0/-46.1
|
12.5/-2.7
|
-12.8/-3.2
|
|
T: Miscellaneous
|
40.4/24.7
|
-40.3/20.2
|
-50.5/-42.1
|
-5.8/-1.8
|
14.9/33.8
|
|
I: Operating system
|
-43.0/6.0
|
704.2/9.5
|
276/-56.0
|
-3.6/-8.8
|
-27.4/-9.1
|
|
I: Backup
|
206/-5.7
|
-207/-16.6
|
-246/-80.0
|
-25.2/-5.5
|
256/-5.7
|
|
I: Audio
|
244/-2.2
|
-45.7/-3.8
|
461/90.7
|
-2.0/-2.6
|
-4.7/0.3
|
|
I: Data
|
-24.3/2.5
|
-137/-6.4
|
120/60.0
|
-12.8/-2.0
|
-23.5/-4.4
|
|
I: Security
|
7.0/14.5
|
85.2/20.8
|
49.8/18.3
|
65.1/20.1
|
12.1/2.0
|
|
I: Games
|
38.5/1.0
|
11.6/10.8
|
711/907
|
9.1/-0.2
|
-7.4/-0.5
|
|
I: Miscellaneous
|
59.3/15.8
|
50.7/28.4
|
48.2/-22.5
|
4.7/-1.5
|
103/50.1
|
based systems), rare extensions, double extensions, long extensions,
repeated patterns in the file path, photograph extensions, executable
extensions, query extensions, installation
extensions, miscellaneous extensions under 100 occurrences, audio directories,
security directories, and game directories. But there were also significant
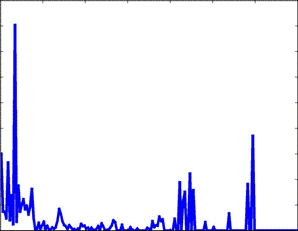
peaks (Fig. 1) in the fraction of malicious files for 16 drives and 296 drives
that were higher than that for 1 drive (drive-unique hashes), so popularity of
a hash value is no guarantee of safety.
Particular extensions, directories, and file names that
were significant malware clues were also identified. These included some
familiar suspects. For the Bit9-flagged data, the most suspicious file names
were autorun.inf (19522 significance), autorun.exe (51.8), _utorun.inf (6925),
install.exe (93.2), patch.exe (65.6), zvregmon.exe (250.8), flashget.exe
(115.3), keygen.exe (395.1), adminserver.dll (180.8), and setup.ini (25.7).
Effects
of the whitelist choice for malware clues were also compared for the four
whitelists (including the consensus one) described in section 2. This had less
effect than varying the blacklists since only 13 rows of the 34 rows shown in
Tables III and IV had significant disagreements in the sign of any clue
strength, so the consensus whitelist values are probably the best guide to
malware clue strength.
IV. Reducing the
Time to Find Malware
One use of these
results is to reduce the amount of time needed to find malware on a system.
Malware could hide anywhere, but our conditional probabilities enable us to
rank its likelihood from context. This is useful in designing partial "quick
scans" for malware.
To test this, the set
of hash values in our corpus was split randomly. Files were found
corresponding to the two half-sets of hash values, about 124 million files
each. Conditional probabilities for the clues discussed above were calculated
and converted into odds for one half of the corpus. Additional clues that were
tested were the actual file extension, top-level
directory, bottom-level
directory, and file name. Clues relating to the times of the file were
excluded, however, because prediction is the goal and there is no guarantee
that current time patterns will reoccur. Clues were only included if they
occurred at least R times and were significant at a level greater than 2.0
standard deviations above or below the expected value. Clues were then
assessed for each file in the other half of the corpus. Combined assessment
was calculated using a normalization of the Naïve Bayes odds formula:
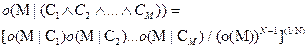
Here M means "file
was malicious" and C means clue. Odds were calculated with Laplace-smoothing
constant K:
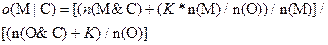 Here n means count, M
means "file is malicious", O means "file is nonmalicious", and K is a constant
that needs to be set. Normalization was necessary because files varied in the
number of significant clues they presented.
Here n means count, M
means "file is malicious", O means "file is nonmalicious", and K is a constant
that needs to be set. Normalization was necessary because files varied in the
number of significant clues they presented.
The two constants R
and K need to be optimized. R represents the threshold for reliable counts on
clues, and K represents the "background noise" of the clue. We did experiments
on a different random sample of 30% of our corpus to vary R and K. Results in
terms of F-score are shown in Table V. The best values appeared to be R=15 and
K=30, so these were used in subsequent experiments.
To test our ability
to rank malware, we set 100 evenly spaced threshold values on the combined odds
and calculated recall (fraction of malware over the threshold) and precision
(fraction of files identified as malware that were actually malware). Recall
is important because a high value reduces the need and rate of doing full scans
for malware, but precision is important too since a low value requires more
files to be scanned of those found. So F-score (the harmonic mean of recall
and precision) was used as the objective function for optimization. Malware
was defined by our consensus list of malicious hashcodes which was the union of
the results of the five malware-identification methods.
We conducted this
experiment three times on three random partitions of our corpus (with a total
of 612,818 instances of malware and 128,776,919 instances of non-malware for
training), using one half for training and one half for testing. The recall
values were 0.343, 0.305 and 0.333; the precision values were 0.213, 0.211, and
0.211; and the resulting F-scores were 0.263, 0.249, and 0.259. So there was
not much
Table
V. Effects of varying R (minimum count) and K (damping constant) on malware
F-score.
|
|
R=10
|
R=20
|
R=40
|
R=100
|
|
K=1
|
.1558
|
.1558
|
.1549
|
.1511
|
|
K=10
|
.1560
|
.1560
|
.1551
|
.1505
|
|
K=30
|
.1566
|
.1566
|
.1548
|
.1505
|
|
K=100
|
.1554
|
.1555
|
.1546
|
.1482
|
variation in the
results, and this tends to support the generality of our corpus for training
purposes. But if one is willing to accept a much lower precision of 0.010 with
our methods, we can obtain a better recall of 0.650. By comparison, selecting
only the executable files gave .005 precision (for 22,940,397 executables
total) and 0.190 recall (for 116,235 malicious executables) for an F-score of
0.0097. Hence our methods give 5.1 times better precision with 1.7 times
better recall over inspecting executables alone. Similarly, selecting only the
files in operating-system top-level directories gave 0.003 precision and 0.189
recall, and selecting only the files in applications top-level directories gave
0.00031 precision and 0.056 recall, so searching for malware in preferred
directories is an even poorer strategy. A possible objection is that malware
in executables, the operating system, and applications directories is more
serious than in other places, but this is questionable since software loads
from many kinds of files today.
Our clues are straightforward
to compute, and can be done on a drive once upon setup, then recalculated every
time a file changes. Note they will be significantly faster to obtain than
signature checking of malware because most involve metadata, with only a few
clues requiring computation of a hash value on a file (something often computed
routinely in investigations). Our methods can also be done before suspected
malicious files are run unlike behavioral analysis. Other methods can also be
used to combine clues such as neural networks and support-vector machines.
To get a quick idea of how our methods compare to standard
tools, we tested Symantec Endpoint Protection installed on a Windows machine.
On a Linux machine without Symantec, we extracted 57 random files previously
identified by Symantec as malicious during downloads from our corpus, mostly
executables since Symantec focuses on those. We did two manipulations to each
file: reversing the bytes of each file and adding (K+1) modulo 256 to the Kth
byte of each file (adding 1 to each byte did not fool Symantec), both of which
gave similar results. We then copied the files to a Windows machine with
Symantec temporarily disabled, undid the manipulation, and placed them in
various places in the secondary storage. Disabling Symantec was necessary
because its normal proactive mode inspects all new files. We then ran an
"active scan: scan only the most commonly infected areas" and Symantec was
unable to detect any of the malicious files; apparently it is only looking in a
few locations. Even when we turned back on the full functionality of the
scanner, it found some residual files only the next day, and caches only a week
later, more than enough time for malware to cause trouble. Symantec’s only
alternative is a "full scan" that did find the malware, but it requires 30-120
minutes according to them and creates significant processing overhead; and
since it appears to look only for files modified since the last scan, it can be
fooled by malware that changes file metadata but not contents. Thus it appears
that Symantec’s only alternative to a full scan looks only at files in certain
directories and not at files by extension.
V. Conclusions
This work is important
in testing a considerably larger corpus of real-world malware than any previous
work. It has shown some surprising things about where malware occurred in real
systems. Malware is not just in executables and system directories, but is
spread over a wide range of files. Some of the classic clues were supported
and some were not. Comparison of different malware-identification methods
showed important differences in clue strengths. These clues can be
supplemented by signature, behavioral, and reputation clues, and by clues
provided by users [14], to provide a broad approach to predicting malware [15].
However, our results raise serious questions about reputation based on
popularity. Another step is to apply clue analysis to meaningful components of
malware to recognize commonalities more easily [16].
Can malware
writers evade our identification methods by deliberately putting malware in
context that does not match our clues? Certainly, but then we have then
increased the cost to them of deploying malware, which is all that any
anti-malware method can do. The situation is similar to that of signature-based
malware detection, where a malware writer can replace a discovered signature
with functional equivalent, but at the cost of their time and effort.
The low rate of
overlap between malware-identification methods suggests that organizations
should not depend on a single anti-malware product to defend their systems.
Our school, for instance, depends heavily on Symantec. Use of a single tool
means many organizations are unprepared to eliminate malware found by other
methods; ad hoc malware removal is time-consuming and may jeopardize normal
functionality. While some of the non-Symantec malware identifications found in
this study may be spurious, it is unlikely that most are, and thus we conclude
that many organizations are vulnerable to a spectrum of malware.
This work focused on local
clues to malware, but other types of suspicious files may also be detectable by
these methods. For instance, persons under criminal investigation will want to
conceal information about their criminal activities using the concealment
methods discussed above plus additional methods such as clustered deletions and
steganography. Our methodology for systematically testing clues on a corpus
can also help for such investigations [11].
Acknowledgement
This work was supported by the
U.S. Navy OPNAV Study program through NPS. Riqui Schwamm and Jeromy Santos
helped with the data processing.
References
[1]
D. Komashinskiy and I. Kotenko, "Malware
detection by data mining techniques based on positionally dependent features,"
Proc. 18th Euromicro Intl. Conf. on Parallel, Distributed, and Network-Based
Processing, pp. 617-623, 2010.
[2]
M. Chandramohan, H. Tan, L. Briand,
L. Shar, and B. Padmanabhuni, "A scalable approach for malware detection
through bounded feature space behavior modeling," Proc. 28th IEEE/ACM Intl.
Conf. on Automated Software Engineering, pp. 312-322, 2013.
[3]
X. Han, J. Sun, W. Qu, and X. Yao, "Distributed
malware detection based on binary file features in cloud computing environment,"
Proc. 26th Control and Decision Conference, pp. 4083-4088, 2014.
[4]
S. Anju, P. Harmya, N. Jagadeesh,
and R. Darsana, "Malware detection using assembly code and control flow graph
optimization," Proc. 1rst Amrita ACM-W Celebration of Women in Computing, 65,
2010.
[5]
L. Chen, B. Liu, H. Hu, and Q. Zheng,
"A layered malware detection model using VMM," Proc. 11th IEEE Intl. Conf. on
Trust, Security, and Privacy in Computing and Communications, pp. 1259-1264,
2012.
[6]
R. McMillan, "AV tests find that
reputation really does count," Computerworld, Sept. 21, 2009.
[7]
McAfee, "Run a quick scan," retrieved
January 11, 2015 from
download.mcafee.com/products/webhelp/4/1033/GUID-D7BD6B9D-E1B5-4E0A-93CA-3F9B32B07DE6.html.
[8]
S. Edwards, "Four fs of
anti-malware testing," Workshop on Anti-Malware Testing Research, October 2013.
[9]
S. Chamotra, R. Sehgal, R. Kamal,
and J. Bhatia, "Data diversity of a distributed honey net based malware
collection system," Proc. Intl. Conf. on Emerging Trends in Networks and
Computer Communications, pp. 125-129, April 2011.
[10] N. Agrawal, W. Bolosky, J. Douceur, and J. Lorch,
"A five-year study of file-system metadata,"
ACM Transactions on Storage, Vol. 3, No. 3, October, pp. 9:1-9:32,
2007.
[11] N. Rowe and S. Garfinkel, "Finding anomalous and
suspicious files from directory metadata on a large corpus," 3rd International
ICST Conference on Digital Forensics and Cyber Crime, Dublin, Ireland, October
2011. In P. Gladyshev and M. K. Rogers (eds.), Lecture Notes in Computer
Science LNICST 88, Springer-Verlag, 2012, pp. 115-130.
[12] A. Mohaisen and O. Alrawi, "An evaluation of antivirus
scans and labels," Proc. 11th Intl. Conf. on Detection of Intrusions and
Malware and vulnerability Assessment, Egham UK, pp. 112-131, July 2014.
[13] eVision, "Malware startup locations: computer forensics
consulting," 2011, retrieved January 7, 2015 from www.evision.com/itc/
360download.php?filename=pdf/Malware _Startup_Locations.pdf.
[14] F. Levesque, J. Nsiempba, J. Fernandez, S Chiasson, and
A. Somayaji, "A clinical study of risk factors related to malware infections,"
Proc. ACM SIGSAC Conference on Computer and Communications Security, pp.
97-108, 2013
[15] E. Gandotra, D. Bansal, and S. Sofar, "Integrated
framework for classification of malwares," Proc. 7th Intl. Conf. on Security of
Information and Networks, 417, September 2014.
[16] B. Ruttenberg, C. Miles, L. Kellogg, V. Notani, M.
Howard, C. LeDoux, A. Lakhotin, A., and A. Pfeffer, "Identifying shared
software components to support malware forensics," Proc. 11 Intl. Conf. on
Detection of Intrusions and Malware and Vulnerability Assessment, Egham UK, pp.
21-40, July 2014.