Understanding of technical captions via statistical parsing
Neil C. Rowe
Code CS/Rp, Department of Computer Science
Naval Postgraduate School,
Monterey, CA USA 93943,
rowe@cs.nps.navy.mil
Abstract
A key problem in indexing technical information is its use of unusual
technical words and word senses. The problem is important for
technical captions on images, whose pithy descriptions can be valuable
to decipher. Our approach is to provide general tools for lexicon
enhancement with the specialized words and word senses, and to learn
word usage information from a training corpus using a statistical
parser. We describe the natural-language processing for MARIE-2, a
natural-language information retrieval system for multimedia captions.
We use statistics on both word senses and word-sense pairs to guide
parsing. Innovations of our approach are in statistical inheritance
of binary co-occurrence probabilities and in weighting of sentence
subsequences. MARIE-2 was tested on 437 captions (with 803 distinct
sentences) from the photograph library of a Navy laboratory. The
captions had extensive noun compounds, code phrases, abbreviations,
and acronyms, but few verbs, abstract nouns, conjunctions, and
pronouns. Experimental results fit a time in seconds of |0.0858 n sup
2.876| and a number of tries before finding the best interpretation of
|1.809 sup n sup 1.668| where |n| is the number of words in the
sentence. Use of statistics from previous parses definitely helped in
reparsing the same sentences; it initially hurt performance on new
sentences, but performance stabilized with further sentences.
Word-sense statistics helped dramatically; statistics on word-sense
pairs helped but not always.
This work was sponsored by DARPA as part of the I3 Project under AO
8939, by the Army Artificial Intelligence Center, and by the
U. S. Naval Postgraduate School under funds provided by the Chief for
Naval Operations. Thanks to Albert Wong for programming help.
Introduction
Our MARIE project has been investigating information retrieval of
multimedia data by emphasizing caption processing. Although media
content analysis such as image processing eliminates the need to
examine captions, caption processing can be much faster since captions
summarize important content in an often-small number of words.
Checking captions before retrieving media data can rule out bad
matches quickly, and captions can provide information not in the media
like the date or customer for a photograph.
Some natural-language processing of captions is necessary for high
query recall and precision. Processing must determine the word senses
and how the words relate to get beyond the well-known limits of
keyword matching (Krovetz and Croft, 1992). This is a challenge for
specialized technical dialects. Automatic indexing for them could
have a high payoff if few people currently can understand the
captions. But linguistically such dialects offer (1) unusual words,
(2) familiar words in unusual senses, (3) code words, (4) acronyms,
and (5) new syntactic features. It is not cost-effective to hand-code
all such specifics for every technical dialect. We need to infer most
of them from analysis of a representative technical corpus. And then
to handle the unusual features of the dialects, we should mix
traditional symbolic parsing with probabilistic ranking from
statistics.
While the MARIE project is intended for multimedia information
retrieval in general, we have used as testbed the Photo Lab of the
Naval Air Warfare Center (NAWC-WD), China Lake, California USA. This
is a library of about 100,000 pictures with 37,000 captions for those
pictures. The pictures cover all activities of the center, including
pictures of equipment, tests of equipment, administrative
documentation, site visits, and public relations. With so many
pictures, many incomprehensible to ordinary people, captions are
indispensable to find anything. But the existing computerized keyword
system for finding pictures from their captions is unhelpful, and is
mostly ignored by personnel.
(Guglielmo and Rowe, 1996) reports on MARIE-1, a prototype system that
we developed for NAWC-WD, a system that appears more in the direction
of what users want. MARIE-1 followed traditional methods of
natural-language processing for information retrieval (Grosz et al,
1987; Rau, 1988; Sembok and van Rijsbergen, 1990) using hand-coded
lexicon information. But MARIE-1 took a man-year to construct and
only handled 217 pictures (averaging 20 words per caption) from the
database, and its coverage of unexpected questions is rather
inaccurate. To do better, MARIE-2 uses statistical parsing and a
number of training methods. Development encountered some interesting
problems, and provides a good test of the application of statistical
parsing ideas to an unfiltered real-world dialect. MARIE-2's parser
is implemented in semi-compiled Quintus Prolog and took 5600 lines of
source code to specify.
Example captions
To illustrate the problems, here are example captions from NAWC-WD.
All are single-case.
an/apq-89 xan-1 radar set in nose of t-2 buckeye modified aircraft bu#
7074, for flight evaluation test. 3/4 overall view of aircraft on runway.
This is typical of many captions: two noun phrases, each terminated
with a period, where the first describes the photographic subject and
the second describes the picture itself. Also typical are the complex
nominal compounds, "an/apq-89 xan-1 radar set" and "t-2 buckeye
modified aircraft bu# 7074". Domain knowledge is necessary to
recognize "an/apq-89" as a radar type, "xan-1" a version number for
that radar, "t-2" an aircraft type, "buckeye" a slang additional name
for a T-2, "modified" a conventional adjective, and "bu# 7074" as an
aircraft code ID. Note that several words here change meaning when
they modify other words. Thus the nonsyntactic approach of the
indexing system of (Silvester et al, 1994) for a similar domain has
limitations here.
program walleye, an/awg-16 fire control pod on a-4c bu# 147781
aircraft, china lake on tail, fit test. 3/4 front overall view and
closeup 1/4 front view of pod.
This illustrates some domain-dependent syntax. "A-4c bu# 147781" is
a common pattern of <equipment-type> <prefix-code> <code-number>,
"an/awg-16 fire control pod" is a common pattern of <equipment-name>
<equipment-purpose> <equipment-type>, and "3/4 front overall view" is
of the form <view-qualifier> <view-qualifier> <view-type>.
graphics presentation tid progress 76. sea site update, wasp head
director and hawk screech/sun visor radars. top portion only,
excellent.
This illustrates the need for domain-dependent statistics on word
senses. Here "wasp", "hawk", "screech", and "sun visor" should not be
interpreted in their common English word senses, but as equipment
terms. Furthermore, "progress 76" means "progress in 1976",
"excellent" refers to the quality of the picture, the "head director"
is not a person but a guidance system, and the "sea site" is a dry
lakebed flooded with water to a few inches.
aerial low oblique, looking s from inyodern rd at main gate down china
lake bl to bowman rd. on l, b to t, water reservoirs, trf crcl, pw
cmpnd, vieweg school, capehart b housing, burroughs hs, cimarron
gardens, east r/c old duplex stor. lot. on r, b to t, trngl, bar s
motel, arrowsmith, comarco, hosp and on to bowman rd.
This illustrates the common misspellings and nonstandard abbreviations
in the captions. "Trf crcl" is "traffic circle", "trngl" is triangle,
"capehart b" is "capehart base", but "b to t" is "bottom to top".
"Vieweg" which looks like a misspelling is actually a person name, but
"inyodern" should be "inyokern", a nearby town.
In general, syntax rules in this dialect exhibit quite different
frequencies of use compared to everyday English, although only a few
rules are not standard English. Fig. 1 shows some example syntax
rules and their frequencies as computed in the three training sets.
Also words are generally less ambiguous than in everyday English: Of
the 1858 word senses used in the three training sets, 1679 were the
only sense used of their word. Nonetheless, the word senses used are
often not the most common in standard English, and there are many
ambiguities of word relationships that must be resolved.
Lexical issues
Creating the full synonym list, type hierarchy, and part hierarchy for
applications of the size of the NAWC-WD database (42,000 words in
37,000 captions, including words closely related to those in the
captions) is considerable work. Fortunately, common words are covered
already by Wordnet (Miller et al, 1990), a large thesaurus system that
includes synonym, type, and part information, plus rough word
frequencies and morphological processing. Wordnet provided basic
information for about 6,000 words in the NAWC-WD captions (or about
24,000 word senses).
This left about 22,000 unidentified words which were handled in
several different ways (see Fig. 2). One class is defined-code
prefixes like "f-" in "f-18" for fighter aircraft, or like "es" in
"es4522" for test numbers. There are several hundred special-format
rules, which interpret "BU# 462945" as an aircraft identification
number by its front word, "sawtooth mountains" as mountains by its
tail word, "02/21/93" as a date, "10-20m" as a range of meters,
"visit/dedication" as a conjunction, and "ship-loading" as a
noun-gerund equivalent of an adjective. Misspellings and
abbreviations were obtained mostly automatically, with human
post-checking, using the methods described in (Rowe and Laitinen,
1995). Forms of lexical ellipsis (e.g. "356" after "LBL 355") are
also covered. Other classes of words specially handled are technical
words from MARIE-1, morphological variants on known words, numbers,
person names, place names, and manufacturer names. 1700 words needed
explicit definition by us in the form of part of speech and
superconcept or synonym. The remaining unclassified words are assumed
to be equipment names, a usually safe assumption. The effort for
lexicon-building was relatively modest (0.3 of a man-year) thanks to
Wordnet, which suggests good portability.
Wordnet also provided us with 15,000 synonyms for the words in our
lexicon, and we provided additional synonyms for technical word
senses. For each set of synonyms, we picked a "standard synonym".
Pointers go from all other synonyms to the standard synonym, the only
synonym for which detailed lexical information like superconcepts is
kept.
We put all lexicon information in Prolog format. The meaning assigned
to a noun or verb in a caption is that of a subtype of its concept in
the type hierarchy, and other parts of speech correspond to properties
or relationships of such subtypes. Typically, each word of the input
caption maps to one two-argument predicate expression in the semantic
representation ("meaning list") of the caption. For instance, "Navy
aircraft on runway" after parsing has the meaning list:
[a_kind_of(v3,aircraft-1), owner(v3,'USN'-1), over(v3,v5), a_kind_of(v5,runway-1)]
where v3 and v5 are variables, and the numbers after the hyphen
are word sense numbers.
Parsing
We chose to use a simple grammar and relatively simple semantic rules,
to see how far we could rely on statistics in lieu of subtler
distinctions (an idea similar to that of (Basili et al, 1992)). For
instance, the NAWC-WD corpus frequently shows a type of aircraft
followed by "bu#" and an identification number for the aircraft; we
use a generic rule for noun-noun compounds for things of similar
types, and let statistics tell us that BU numbers often follow
aircraft. Our full grammar has 192 syntax rules, 160 binary
(two-term) and 32 unary (one-term), and 71 of the binary rules are
context-sensitive. The context-sensitivity is modest and unnecessary
for correct parsing, but helps efficiency on long sentences. For
instance, an appositive that starts with a comma must be followed by
comma except at the end of a sentence, and modifying participial
phrase followed by a comma and a noun phrase can only occur at the
front of a sentence.
Binary rules have associated semantic rules (114 in all including one
default rule) that check semantic consistency, calculate the total
probability, and compute the resulting meaning list. 14 of the
semantic rules were specific to the dialect. Semantic rules are
particularly detailed for three common constructs in technical
description: noun-noun compounds, appositives, and prepositional
phrases. Rules for noun-noun compounds cover 55 cases like
type-subtype ("f-18 aircraft"), type-part ("f-18 wing"), owner-object
("navy f-18"), object-action ("f-18 takeoff"), action-object
("training f-18"), action-location ("training area"), object-concept
("f-18 project"), and type-type ("f-18 harrier"). Rules for
appositives cover 24 similar cases like those plus additional ones for
things like object-action ("wings (folded)"). Rules for prepositional
phrases checked case compatibility of preposition with both subject
and object. For instance, the object of the location-preposition
meaning of "in" could only be a location, event, range, or view; its
subject could be only a location or event.
We use a kind of bottom-up chart parser (Charniak, 1993, chapter 6).
We work separately on each sentence of a caption. Using unary
word-sense statistics (see below), the most likely interpretation for
each word is entered in the chart (no part-of-speech tagging from
context (Brill, 1995) is currently done, though that might improve
performance). We then do a branch-and-bound search. All word and
phrase interpretations are indexed and rated; the best unexamined
interpretation is chosen to work on at each step. All word and phrase
interpretations that adjoin it (without gaps) to the left and right
are considered for combination, checked against grammar rules, if
successful checked against semantic rules, and then if successful
ranked and added to the set of word and phrase interpretations. With
this approach, only redundant interpretations are ever deleted, to
prevent missing anything. The first interpretation found that covers
all the words and corresponds to the grammatical category "caption" is
the answer, except during training when the first interpretation is
presented to the user (or "trainer") for approval, then the second
interpretation found, and so on until the trainer accepts one. Upon
acceptance, conjunct simplification and anaphoric-reference resolution
are done (using results for previous sentences of a multi-sentence
caption), and the result is cached (occasionally identical captions
occur). If no satisfactory interpretation is found, the next-best
unexplored word sense is added to the chart and parsing continues.
This is done as many times as necessary. If parsing still fails, the
best pieces of interpretations are assembled for a partial
interpretation.
Unary statistics
Wordnet is based on traditional printed dictionaries and distinguishes
many word senses. Thus a key factor in finding the best sentence
interpretation are the estimated likelihoods of word senses obtained
by extrapolating from the counts observed in the training corpus.
(Estimates are necessary since the corpus can only cover a small
fraction of English word senses.) These likelihoods use counts from
the word sense itself ("unary counts") and all the neighboring word
senses in the type hierarchy. For instance, Sidewinder sense 1 is a
missile and a missile is a weapon; there are 3733 mentions of
"missile" in the corpus, and 1202 mentions of "weapon". Sidewinder
sense 2 is a rattlesnake and a rattlesnake is a snake; there are 7
mentions of "rattlesnake" and 6 of "snake". We attenuate neighboring
counts by a factor of 2 per link traversed; so for "Sidewinder" sense
1, "missile" contributes 3733/2 = 1866.5 and "weapon" contributes
1202/4 = 300.5. We limit search to three links from the starting
point in the experiments reported here, and consider both upward
(superconcept) and downward links. For "sidewinder", we got a
weighted total count of 1094 for the missile sense and 497 for the
snake sense.
Three additional points must be noted. First, the unary counts must
include "indirect" counts too, or those of all subtypes; this permits
judging the likelihood of rare senses. Second, if the word sense has
a standard synonym, then the synonym is a neighbor (separate counts
are kept for each synonym). Third, if there are multiple
superconcepts, as when iron is both an element and a metal, both get
the same full weight because both fully apply.
Training counts can often quickly indicate the common specialized word
senses used in a technical dialect. This means MARIE-2 learns from
experience, by information extracted from meaning lists accepted by
the trainer. Computation of indirect counts is time-consuming, so
recalculation was done only after each training set. Initial counts
were obtained from the counts of all the raw words in all the 36,191
captions, apportioning the count for each word equally among its
possible senses; senses other than noun, verb, adjective, or adverb
were assumed to occur 80% of the time to prevent overweighting noun
senses like "can" as a container and "a" as a shape.
Binary statistics
Statistical parsing usually exploits the probabilities of strings of
successive words in a sentence (Jones and Eisner, 1992; Charniak,
1993). Binary statistics (the counts of the co-occurrence of pairs of
words) fit naturally to our binary parse rules, as the likelihood of
co-occurrence of the two subparses, as an alternative to more complex
semantic restrictions (Basili et al, 1996). For example, parsing
"f-18 landing" with the rule "NP -> NP PARTICIPLEPHRASE" should be
good because F-18s often land, unlike "upstairs" in "upstairs
landing". Estimates of co-occurrence probabilities can inherit in a
type hierarchy (Rowe, 1985). So if we have insufficient data on how
often an F-18 lands, we may have enough on how often an aircraft
lands; and if F-18s are typical aircraft in this respect, how often
F-18s land is the product of the "aircraft lands" count and the ratio
of the count on "F-18" to the count on "aircraft". Both word senses
can be generalized in searching for counts, so we can use statistics
on "F-18" and "moving", or on "aircraft" and "moving". Or we can go
further up the type hierarchy to get statistics on "vehicle" and
"moving". The idea is to find sufficient statistics to fairly
estimate the co-occurrence probability of the words. It also makes
sense to lump counts on all morphological variants together, so the
count on "F-18" and "land" would also cover the noun phrase "the usn
f-18s just landed".
For manageability and statistical reliability, we limit counts to
those of no more than two words (but taking multiword proper nouns
as a single word). In combining multiword sequences, we use the
counts of the most important words or "headwords". For instance, "the
big f-18 from china lake landing at armitage field" can also be parsed
by "NP -> NP PARTICIPLEPHRASE" with the binary count for "f-18" and
"landing" used, since "f-18" is the principal noun and hence headword
of "the big f-18 from china lake", and "landing" is the participle and
hence headword of "landing at armitage field". Headwords of phrases
are usually obvious. The binary limitation is consistent with the
importance of cases (a fundamentally binary concept) with most
technical noun-phrase language, but will miss some occasionally
important more-distant relationships in sentences, like between
"plane" and "landing" in "the plane that crashed in the Norfolk
landing". We think these are too rare to be of concern in most
technical dialects.
Each count should be categorized by parse rule, so the alternative
parse of "f-18 landing" by "NP -> ADJECTIVE GERUND" would refer to
different counts. To help with nominal compounds and appositives,
which can be difficult, we further subcategorize counts by the
relationship postulated between the two headwords. For instance,
"evaluation facilities" could mean either the facilities are the agent
of the evaluation or the evaluation occurs at the facilities. Thus we
keep separate statistics for each noun-noun relationship.
One advantage of inheritable binary counts is in identification of
unknown words. Though we do not exploit this yet, categories for the
unknown words can be inferred by their likelihood of accompanying
neighboring word senses. For instance, in "personnel mounting ghw-12
on an f-18", "ghw-12" must be equipment because of the high
likelihoods of co-occurrence of equipment terms with "mount" and "on".
During training, binary count statistics are initially unused. They
are computed from the accepted sentences after each training set has
been run, as a kind of bootstrapping (Richardson, 1994). Counts are
incremented for each node of the parse tree, as well as for all
superconcepts of the words involved, so a co-occurrence of "Navy" and
"Sidewinder" is also a co-occurrence of "Navy" and "missile",
"organization" and "Sidewinder", and "organization" and "missile".
(There are exceptions for code words, numbers, and dates: We only keep
statistics on their superconcepts.) Counts are also computed on
grammar rules by adding the relevant word-pair counts.
The storage for binary counts required careful design because the data
is sparse and there are many small entries. For instance, for the
NAWC-WD captions there are about 20,000 synonym sets about which we
have lexicon information. This means 200 million possible
co-occurrence pairs, but the total of all their counts can only be
610,182, the total number of word instances in all captions. Our
binary counts data structure uses four search trees indexed on the
first word, the part of speech plus word sense of the first word, the
second word, and the part of speech plus word sense of the second
word. Various compression techniques could further reduce storage,
like the idea of omitting counts within a standard deviation of the
predicted value (Rowe, 1985). The standard deviation when |n| is the
size of the subpopulation, |N| is the size of the population, and |A|
the count for the population, is |sqrt { A ( N - A ) ( N - n ) / n N
sup 2 ( N - 1 ) }| (Cochran, 1977).
Control of parsing
Our parser uses four factors to rank possible phrase interpretations:
(1) the unary counts on the word senses, (2) the counts on the grammar
rules used, (3) the binary counts on the headword senses conjoined in
the parse tree, and (4) miscellaneous factors like the distance
between the two headwords and compatibility of conjuncts in length and
type. It is usual to treat these like probabilities (ignoring for now
some normalization factor) and multiply them to get the likelihood
(weight) for the whole sentence (Fujisaki et al, 1991). For an n-word
phrase we can use:
weight = l sup n-1 PI sub i=1 sup n [ n ( w sub i ) ]
PI sub j=1 sup n-1 [ n ( g sub j ) ] PI sub j-1 sup n-1 [ a ( g
sub j ) ] PI sub j-1 sup n-1 [ m ( g sub j ) ]
where |l| is a constant controlling our bias towards longer phrases,
|n ( w sub i )| is the count of the word sense chosen for the
ith word in the phrase, |n ( g sub j )| the count of the grammar
rule used at the jth (in preorder traversal of the parse tree)
binary-rule application in the parse of the phrase, |a ( g sub j )|
is the degree of association of the headwords of the subphrases joined
by the jth binary rule, and |m ( g sub j )| are miscellaneous
weighting factors.
If we take the negatives of the logarithm of the weight, the problem
becomes one of finding a minimum-cost sentence interpretation, where
the cost is computed by adding factors from all parts. Then the
challenge of parsing is to estimate which phrase interpretations are
most likely to lead to good sentence interpretations, which means
estimating cost factors for subphrase combinations not yet known.
Since the A* algorithm is provably optimal and addresses this sort of
problem, we use a variant on it. For true A*, we need lower bounds on
costs (from upper bounds on likelihoods before taking the negatives of
the logarithms) of the remaining factors and remaining words in the
sentence. For the unary-counts factor, we can take the count of the
most common sense of a word. For the grammar-rule factor, we can take
the count of the most common grammar rule. But the binary-counts
factor is unbounded since the degree of association can vary
enormously depending on the corpus, and the miscellaneous factors are
hard to scale. Thus, we will not scale them and do not have a true A*
algorithm, though will use its mechanics. This gives a revised
formula:
weight = l sup n-1 PI sub i=1 sup n [ f ( w sub i ) ]
PI sub j=1 sup n-1 [ f ( g sub j ) ] PI sub j-1 sup n-1 [ a ( g sub j ) ]
PI sub j-1 sup n-1 [ m ( g sub j ) ]
where |l| is a constant; |f ( w sub i )| is the count of the ith word
sense in the sentence divided by the count of the most common sense of
that word; |f ( s sub j )| is the count of the grammar rule used at
the jth binary-rule application divided by the count of the most
common grammar rule; |a ( g sub j )| is the degree of association of
the two headwords of the subphrases joined by the jth binary rule; and
|m ( g sub j )| is the summary of miscellaneous factors on the jth
binary rule. The |l| is automatically increased periodically when the
system has trouble finding a sentence interpretation, and is also
adjusted either up or down when any sentence interpretation found to
try to keep sentence weights in the range of 0.1 to 10.0; this reduces
the tendency of the parser to get stuck on sentences with unfamiliar
word-sense combinations.
The degree of association can be approximated by the ratio of the
observed count of the two headwords in this syntactic relationship to
expected count. The expected count can be estimated from a log-linear
model, which means the count of this syntactic relationship in the
corpus times the proportional frequency of the two word senses in the
corpus:
a ( s sub j ) =
[ b ( w sub j1 , w sub j2 ) n ( g ( w sub j1 ) ) n ( g ( w sub j2 ) ) ] /
[ b ( g ( w sub j1 ) , g ( w sub j2 ) ) n ( w sub j1 ) n ( w sub j2 ) ]
where |b| is the binary frequency, |n| the unary frequency, |j1| the
first word sense, |j2| the second word sense, and |g| the topmost
generalization of the word sense (which for Wordnet is "entity" sense
1 for nouns and "act" sense 2 for verbs). This is greater than 1 for
positively associated words, and less than 1 for negatively associated
words. A default minimum of 0.01 is put on word combinations with no
statistics.
Take the example sentence "pod on f-4"; Fig. 3 shows the full set of
phrase interpretation records created. The first argument to each is
the index number (and creation order) of each entry; the second and
third arguments are the starting and ending numbers of the words in
the input sentence which the entry covers; the fourth argument is the
part of speech; the fifth the meaning list; the sixth the
backpointer(s) to the source entry or entries; and the seventh the
weight. Entries 1-29 in Fig. 3 cover single words and represent the
initial data, the starting agenda for the search. For "pod on f-4" we
found three Wordnet senses of "pod" as a noun (fruit, animal group,
and container) and one domain-dependent verb sense (meaning to put
something into a container). Only the third noun sense occurred in
the training corpus, so it was given a unary weight of almost 1 and
the other noun senses the default of 0.015; "pod" as a verb got a
still smaller weight of 0.0005 since the root verb form is rare and
true verbs are statistically much rarer than participles in this
database. "On" can be a location preposition, an orientation
preposition, a time preposition, or an adverb; only the first sense
occurs in the corpus, so it got a unary weight of 1 and the others
0.002. "F-4" is unambiguous and gets a weight of 1. Each word sense
is then generalized by all possible unary parse rules; so a noun can
be an "ng", an "ng" can be an "adj2", and an "adj2" can be an "np".
For grammar terms with multiple generalizations (as when an "ng" can
be an "np" as well as an "adj2"), the weight is split between the
generalizations, so "pod-3" as an "np" gets a weight of 0.5.
Of the three items on the starting agenda that tie for largest weight,
the location interpretation of "on" was chosen arbitrarily to combine
with other agenda items. Combining it with the word to its right, we
got entry 30 with the subphrase "on f-4" having meaning list
[on(v6,v12), a_kind_of(v12,'F-4'-0)]. This got a computed
weight of |0.999 * 0.5 * 1 * 1.018 * 1 = 0.509| from respectively
the weight for this interpretation of "on", the weight for "F-4", the
rule-strength weight (since this is the only rule that creates a pp),
the degree of association of 1.018 of "on" and "F-4" (inherited from
the degree of "on" and "fighter" sense 4, the aircraft sense), and 1
for the absence of miscellaneous factors. Eventually the search chose
entry 30 to work on, and combining it with the three noun senses of
"pod" generated entries 31, 33, and 35, which were immediately
generalized to the grammatical category "caption" by a unary parse
rule to get entries 32, 34, and 36. Entry 35 got a much higher weight
than the others from the calculation |0.5 * 0.509 * 1 * 1.377 * 1 =
0.351| where 0.5 is the weight for "pod" sense 3, 0.509 the weight
for "on F-4", 1 the rule weight, 1.377 the degree of association of
"pod" sense 3 and "on" (an association that did occur in the training
corpus and did not have to be inherited), with no miscellaneous
factors. Entry 36 is the final answer, but search continued for a
while until all potentially better candidates on the agenda had been
explored.
Fig. 4 shows a longer example, and compares MARIE-2 parser output with
MARIE-1 for a caption from the first training set. Wordnet
superconcept senses are also provided. MARIE-1's output is less
precise (without word senses and with very general predicate names),
more complex, and shows the effects of overly specialized rules as in
the handling of the coordinates. MARIE-1 could not connect sentences,
and also erred in identifying a DVT-7 as equipment and "run 2" as the
direct object of a test. In general, MARIE-2's meaning lists were
significantly more accurate than those of MARIE-1 because we could
force backtracking during training to get the best representation of a
caption, not just an adequate one, and the significantly more complex
grammatical and semantic features of MARIE-2 helped.
During training runs we permitted trainer feedback to rule out
particular wrong word senses and particular wrong word relationships
in a sentence interpretation (but could cite only one per sentence
interpretation, to keep our statistics meaningful for the number of
tries). So the trainer could tell the parser to rule out "sidewinder"
sense 2, part-whole relationships, past participles, conjunctive
connections, or even a specific predicate expression saying an
aircraft sense 1 possessed a sidewinder sense 2.
Experiments
We used successively three training sets in our experiments.
Statistics are shown in Fig. 5. The first set was the full 217
captions handled by MARIE-1 (Guglielmo and Rowe, 1996). These were a
from the NAWC-WD Photo Lab, and were originally created from a random
sample of supercaptions (captions on classes of pictures), locating
the actual caption folders, and transcribing what was written on the
folders. Since captions for the same supercaption are closely
related, many of the captions had similar wording. Some correction of
errors in the captions was done as explained in the earlier paper.
Initial approximate unary statistics on all word senses in the corpus
were estimated from frequencies of neighbor words. After training on
this set, we calculated word-sense statistics and ran the second
training set using them. The second set was a different random sample
of 108 supercaptions alone with little redundancy. No manual
correction of errors was done, and these captions were difficult to
parse. The third set were 112 manually-extracted captions
constituting nearly all the captioned images available on the NAWC-WD
World Wide Web site in June 1997. These had more polished language
and used some grammatical constructs heretofore unseen like
conjunctive adjectives and relative clauses, but were mostly not
difficult to parse. These captions were not used during our initial
lexicon contruction and they required definition of a number of new
word senses. We ended with counts on 1931 word senses and 4018
word-sense pairs used. Development and testing took about a man-year
of work.
Successful parses were found for all but two ungrammatical sentences
of the first training set. We forced the system to backtrack until it
found the best possible interpretation of the sentence, debugging the
parser when necessary. Fig. 6 shows the full distribution of parse
times in CPU seconds (using semi-compiled Quintus Prolog) for the 437
captions as a function of sentence length in number of words; both
axes display the natural logarithms of their quantities. Significant
variation is apparent. Figs. 7 and 8 show average (geometric mean)
parse CPU time and number of tries for each possible sentence length,
again as logarithms; the dotted line is the first training set, the
thick solid line is the second, and the thin solid line is the third.
It can be seen that parse time and number of tries increased on the
second training set due to the increased parser complexity after
debugging, but not for the third training set subsequently. This
suggests that initialization effects are now fading and performance
will remain constant or improve with further training captions. Also
note all the curves have a linear trend in these log-log plots. We
applied least-squares regression to all the logarithm data to get a
fit for the time in seconds of |0.0858 n sup 2.876| and for the number
of tries of |1.809 n sup 1.668|, where |n| is the number of words in
the sentence, and with degrees of significance of 0.531 and 0.550
respectively. The fit is not great, but does give a rough way to
predict performance.
Fig. 9 lists some representative sentences of medium length from the
third training set. Fig. 10 shows parse CPU time and number of
required tries before obtaining the best interpretation for each. The
first pair of numbers are during training using statistics from the
first two training sets. The second pair of numbers are from
rerunning after including statistics from all of the third training
set. It can be seen that training helps but not much on shorter
sentences; the best improvement was for the last sentence with
statistical hints that the unusual constructs of gerunds and
prepositional adverbs were being used. The third pair of numbers in
Fig. 10 are for conditions like the second except without using any
binary word-sense statistics. Apparently binary statistics could hurt
some sentences a little (by extra time for inheritance), but could
help in longer sentences like the seventh with its many nominal
compounds. The fourth pair of numbers in Fig. 10 are conditions like
the second except without unary statistics, so that all word senses
were rated equally likely. This hurts performance significantly,
suggesting that much of the value in training for this dialect is in
learning the common word senses.
Queries
We also provide a natural-language query capability with the parser.
An English query obtained from the user is parsed and interpreted.
Its variables are given special names different from caption-variable
names, and tense and number markings are eliminated. "Coarse-grain
matching" is then done to find captions containing every type, or its
subtype, mentioned in the query; this idea was followed in MARIE-1,
but here we parse first to get the types more accurately. This
requires a full index on all types mentioned in the caption. Caption
candidates passing the coarse-grain match are then subject to
"fine-grain matching" of the full query meaning list to the full
caption meaning list. This is a standard nondeterministic match with
backtracking, and must be an exact match. We use the reasonable
heuristic that the correct interpretation of an ambiguous query is the
highest-ranking interpretation that has a non-null fine-grain match,
and we backtrack as necessary until we find such an interpretation.
Pictures corresponding to the matched captions are then displayed.
Conclusions
We have attempted a difficult task of parsing substantial sentences in
a specialized real-world dialect with unusual new word senses,
creative syntax, and errors. Our results show it can be done, and
statistical parsing helps, but that much work is required. We expect
that eventually performance should improve with training on further
sentences from the corpus, but we have not yet reached that point as
we still encounter new syntactic constructs and semantic relationships
after 803 carefully-parsed sentences. We hope our experiments will be
helpful for other researchers addressing the many specialized
technical dialects for which automated understanding can be highly
valuable.
References
Basili, R., Pazienza, M., and Velardi, P. A shallow syntactic
analyzer to extract word associations from corpora. Literary
and Linguistic Computing, 7, 2 (1992), 114-124.
Basili, R., Pazienza, M. T., and Velardi, P. An empirical symbolic
approach to natural language processing. Artificial Intelligence,
85 (1996), 59-99.
Brill, E. Transformation-based error-driven learning and natural
language processing: A case study in part-of-speech tagging.
Computational Linguistics, 21, 4 (December 1995), 543-565.
Charniak, E. Statistical Language Learning. Cambridge, MA: MIT
Press, 1993.
Cochran, W. G. Sampling Techniques, third edition. New York:
Wiley, 1977.
Fujisaki, T., Jelinek, F., Cocke, J., Black, E., and Nishino, T. A
probabilistic parsing method for sentence disambiguation. In
Current issues in parsing technology, ed. Tomita, M., Boston:
Kluwer, 1991.
Grosz, B., Appelt, D., Martin, P. and Pereira, F. TEAM: An
experiment in the design of transportable natural language interfaces.
Artificial Intelligence, 32 (1987), 173-243.
Guglielmo, E. and Rowe, N. Natural language retrieval of images based
on descriptive captions. ACM Transactions on Information Systems,
14, 3 (May 1996), 237-267.
Jones, M. and Eisner, J. A probabilistic parser applied to software
testing documents. Proceedings of the Tenth National Conference on
Artificial Intelligence, San Jose, CA, July 1992, 323-328.
Krovez, R. and Croft, W. B. Lexical ambiguity and information
retrieval. ACM Transactions on Information Systems, 10, 2
(April 1992), 115-141.
Miller, G., Beckwith, R., Fellbaum, C., Gross, D., and Miller, K.
Five papers on Wordnet. International Journal of Lexicography,
3, 4 (Winter 1990).
Rau, L. Knowledge organization and access in a conceptual information
system. Information Processing and Management, 23, 4 (1988),
269-284.
Richardson, S. D. Bootstrapping statistical processing into a
rule-based natural language parser. Proceedings of The Balancing Act:
Combining Symbolic and Statistical Approaches to Language, Association
for Computational Linguistics, Las Cruces, NM, July 1994, 96-103.
Also Microsoft Technical Report MSR-TR-95-48.
Rowe, N. Antisampling for estimation: an overview. IEEE
Transactions on Software Engineering, SE-11, 10 (October 1985),
1081-1091.
Rowe, N. and Laitinen, K. Semiautomatic disabbreviation of technical
text. Information Processing and Management, 31, 6 (1995),
851-857.
Sembok, T. and van Rijsbergen, C. SILOL: A simple logical-linguistic
document retrieval system. Information Processing and Management,
26, 1 (1990), 111-134.
Silvester, J. P., Genuardi, M. T., and Klingbiel, P. H. Machine-aided
indexing at NASA. Information Processing and Management, 30,
5, 631-645.
Rule Frequency Example
adj2 + ng = ng 1986 "Navy" + "aircraft"
b_prtp + np = prtp2 107 "testing" + "the seat"
art2 + ng = np 174 "the" + "naval aircraft"
adv + participle = a_prtp 23 "just" + "loaded"
noun + numeric = ng 75 "test" + "0345"
timeprepx + np = pp 60 "during" + "the test"
locprepx + np = pp 639 "on" + "the ground"
miscprepx + np = pp 565 "with" + "instrument pod"
np + pp = np 1115 "Navy aircraft" + "during testing"
np + prtp = np 261 "a crewman" + "loading the pod"
vg + np = vp2 30 "loads" + "the instrument pod"
np + vp = snt 33 "a crewman" + "loads the pod"
vp2 + pp = vp2 14 "loads" + "on the aircraft"
adv + pp = pp 21 "just" + "below the aircraft"
conj + np = cj_np 152 "and" + "aircraft"
np + cj_np = np 177 "sled" + "and dummy"
np + c_aps = np 36 "the aircraft" + ", F-18,"
ng + aps = ng 178 "aircraft" + "(F-18)"
np + aps = np 46 "the aircraft" + "(F-18)"
np + c_np = np 53 "the aircraft" + ", the F-18"
np_c + np = np 50 "sled," + "dummy" [comma fault]
prtp2 + pp = prtp2 116 "just loaded" + "on aircraft"
infinmarker + vp = ip 10 "to" + "load"
conj + vp = cj_vp 3 "and" + "loads the aircraft"
snt + cj_snt = snt 2 "crewmen load" + "and officer directs"
Figure 1: Example syntactic rules with their frequency in the
output of the parser on the three training sets.
Number of captions 36,191
Number of words in the captions 610,182
Number of distinct words in the captions 29,082
Subset having explicit entries in Wordnet 6,729
(Number of these for which a preferred alias is given: 1,847)
(Number of word senses given for these words: 14,676)
Subset with definitions reusable from MARIE-1 770
Subset with definitions written explicitly for MARIE-2 1,763
Subset that are morphological variants of other known words 2,335
Subset that are numbers 3,412
Subset that are person names 2,791
Subset that are place names 387
Subset that are manufacturer names 264
Subset that have unambiguous defined-code prefixes 3,256
(Unambiguous defined-code prefixes: 947)
Subset that are other identifiable special formats 10,179
Subset that are identifiable misspellings 1,174
(Misspellings found automatically: 713)
Subset that are identifiable abbreviations 1,093
(Abbreviations found automatically: 898)
Remaining words, assumed to be equipment names 1,876
Explicitly used Wordnet alias facts of above Wordnet words 20,299
Extra alias senses added to lexicon beyond caption vocabulary 9,324
Explicitly created alias facts of above non-Wordnet words 489
Other Wordnet alias facts used in simplifying the lexicon 35,976
Extra word senses added to lexicon beyond caption vocabulary 7,899
Total number of word senses handled 69,447
(includes related superconcepts, wholes, and phrases)
Figure 2: Statistics on the MARIE-2 lexicon for the NAWC-WD captions after
handling the first training set.
p(1,1,1,verb,[a_kind_of(v1,pod-100),quantification(v1,plural)],[],0.000544).
p(2,1,1,vg,[a_kind_of(v1,pod-100),quantification(v1,plural)],[1],0.000544).
p(3,1,1,vp2,[a_kind_of(v1,pod-100),quantification(v1,plural)],[2],0.000544).
p(4,1,1,vp,[a_kind_of(v1,pod-100),quantification(v1,plural)],[3],0.000544).
p(5,1,1,noun,[a_kind_of(v2,pod-1)],[],0.015151).
p(6,1,1,ng,[a_kind_of(v2,pod-1)],[5],0.015151).
p(7,1,1,adj2,[a_kind_of(v2,pod-1)],[6],0.007575).
p(8,1,1,np,[a_kind_of(v2,pod-1)],[6],0.007575).
p(9,1,1,noun,[a_kind_of(v3,pod-2)],[],0.015151).
p(10,1,1,ng,[a_kind_of(v3,pod-2)],[9],0.015151).
p(11,1,1,adj2,[a_kind_of(v3,pod-2)],[10],0.007575).
p(12,1,1,np,[a_kind_of(v3,pod-2)],[10],0.007575).
p(13,1,1,noun,[a_kind_of(v4,pod-3)],[],0.999969).
p(14,1,1,ng,[a_kind_of(v4,pod-3)],[13],0.999969).
p(15,1,1,adj2,[a_kind_of(v4,pod-3)],[14],0.499984).
p(16,1,1,np,[a_kind_of(v4,pod-3)],[14],0.499984).
p(17,2,2,locprep,[property(v6,on)],[],0.999995).
p(18,2,2,prep,[property(v6,on)],[17],0.999995).
p(19,2,2,miscprep,[property(v7,orientation)],[],0.002439).
p(20,2,2,prep,[property(v7,orientation)],[19],0.002439).
p(21,2,2,adv,[property(v8,on-150)],[],0.002439).
p(22,2,2,timeprep,[property(v9,during)],[],0.002439).
p(23,2,2,prep,[property(v9,during)],[22],0.002439).
p(24,2,2,miscprep,[property(v10,object)],[],0.019512).
p(25,2,2,prep,[property(v10,object)],[24],0.019512).
p(26,3,3,noun,[a_kind_of(v12,'F-4'-0)],[],0.999833).
p(27,3,3,ng,[a_kind_of(v12,'F-4'-0)],[26],0.999833).
p(28,3,3,adj2,[a_kind_of(v12,'F-4'-0)],[27],0.499916).
p(29,3,3,np,[a_kind_of(v12,'F-4'-0)],[27],0.499916).
p(30,2,3,pp,[on(v6,v12),a_kind_of(v12,'F-4'-0)],[[17,29]],0.508953).
p(31,1,3,np,[a_kind_of(v2,pod-1),on(v2,v12),a_kind_of(v12,'F-4'-0)],[[8,30]],0.002336).
p(32,1,3,caption,[a_kind_of(v2,pod-1),on(v2,v12),a_kind_of(v12,'F-4'-0)],[31],0.002336).
p(33,1,3,np,[a_kind_of(v3,pod-2),on(v3,v12),a_kind_of(v12,'F-4'-0)],[[12,30]],0.002341).
p(34,1,3,caption,[a_kind_of(v3,pod-2),on(v3,v12),a_kind_of(v12,'F-4'-0)],[33],0.002341).
p(35,1,3,np,[a_kind_of(v4,pod-3),on(v4,v12),a_kind_of(v12,'F-4'-0)],[[16,30]],0.350505).
p(36,1,3,caption,[a_kind_of(v4,pod-3),on(v4,v12),a_kind_of(v12,'F-4'-0)],[35],0.350505).
p(37,1,3,vp2,[a_kind_of(v1,pod-100),quantification(v1,plural),on(v1,v12),a_kind_of(v12,'F-4'-0)],
[[3,30]],0.000000).
p(38,1,3,vp,[a_kind_of(v1,pod-100),quantification(v1,plural),on(v1,v12),a_kind_of(v12,'F-4'-0)],
[37],0.000000).
p(40,2,3,pp,[object(v10,v12),a_kind_of(v12,'F-4'-0)],[[24,29]],0.009611).
Figure 3: Chart resulting from parse of "pod on f-4".
Input 215669:
"tp 1314. a-7b/e dvt-7 (250 keas) escape system (run 2). synchro firing at 1090' n x 38' w. dummy just leaving sled."
Meaning list computed by MARIE-2:
[a_kind_of(v1,"TP-1314"-0), during(v3,v1), a_kind_of(v3,"escape system"-0), during(v3,v4),
a_kind_of(v4,"RUN 2"-0), agent(v8,v3), a_kind_of(v8,"DVT-7"-0), measurement(v8,v2),
a_kind_of(v2,"250 keas"-0), quantity(v2,250), units(v2,keas), object(v8,v5), a_kind_of(v5,"A-7B/E"-0),
during(v141,v1), a_kind_of(v141,launch-2), property(v141,synchronous-51), at(v141,v95),
a_kind_of(v95,place-8), part_of(v45,v95), part_of(v46,v95), a_kind_of(v45,"1090'' n"-0),
quantity(v45,1090), units(v45,"latitude-minute"-0), a_kind_of(v46,"38'' w"-0), quantity(v46,38),
units(v46,"longitude-minute"-0), during(v999,v1), a_kind_of(v999,dummy-3), agent(v1012,v999),
a_kind_of(v1012,leave-105), tense(v1012,prespart), property(v1012,just-154), object(v1012,v1039),
a_kind_of(v1039,sled-1)]
Superconcept information for the word senses:
"TP-1314"-0 -> test-3, "escape system"-0 -> system-8, "DVT-7"-0 -> test-3,
"250 keas"-0 -> number-7, "A-7B/E"-0 -> fighter-4, "RUN 2"-0 -> run-1, shoot-109 -> discharge-105,
place-8 -> "geographic area"-1, "1090' n"-0 -> number-6, "38' w"-0 -> number-6,
synchronous-51 -> "at the same time"-51, dummy-3 -> figure-9, leave-105 -> go-111, sled-1 -> vehicle-1
Meaning list computed by MARIE-1:
[inst('noun(215669-4-2)',sled), inst('noun(215669-2-a68)','A-7B/E'),
attribute('noun(215669-2-a67)',part_of('noun(215669-2-a68)')),
inst('noun(215669-2-a67)','DVT-7'), agent('prespart(215669-4-1)',obj('noun(215669-4-1)')),
source('prespart(215669-4-1)',obj('noun(215669-4-2)')),
activity('prespart(215669-4-1)',depart), attribute('coordinate(215669-3-1)','1090 '' N x 38 '' W'),
inst('coordinate(215669-3-1)',coordinate), attribute('noun(215669-2-6)','2'),
theme('noun(215669-2-6)',obj('noun(215669-2-5)')), inst('noun(215669-2-6)',run),
theme('noun(215669-2-5)',obj('noun(215669-2-a67)')), quantity('noun(215669-2-5)',keas('250')),
inst('noun(215669-2-5)',test), attribute('noun(215669-3-1)',synchronous),
location('noun(215669-3-1)',at('coordinate(215669-3-1)')),
activity('noun(215669-3-1)',launch), inst('noun(215669-4-1)',dummy),
attribute('noun(215669-1-1)','1314'), inst('noun(215669-1-1)','test plan')]
Figure 4: Example parser output, plus superconcepts for the word senses used.
Training set 1 Set 2 Set 3
Number of new captions 217 108 112
Number of new sentences 444 219 140
Number of total words in new captions 4488 1774 1060
Number of distinct words in new captions 939 900 418
Number of new lexicon entries required c.150 106 78
Number of new word senses used 929 728 287
Number of new sense pairs used 1860 1527 542
Number of lexical-processing changes required c.30 11 7
Number of syntactic-rule changes or additions 35 41 18
Number of case-definition changes or additions 57 30 11
Number of semantic-rule changes or additions 72 57 15
Figure 5: Overall statistics on the training sets.
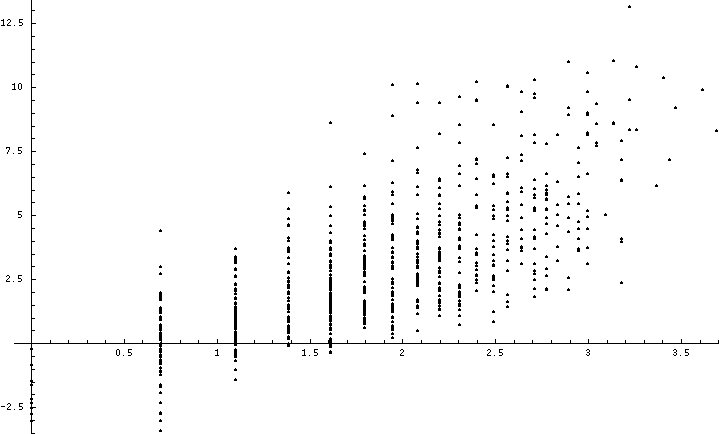
Figure 6: Log of parse time versus log of sentence length.
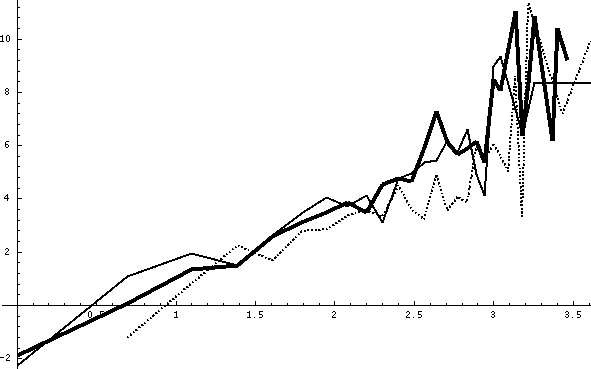
Figure 7: Log of geometric mean of parse time versus log of sentence
length. Dotted line is first training set, heavy line is second,
and thin line is third.
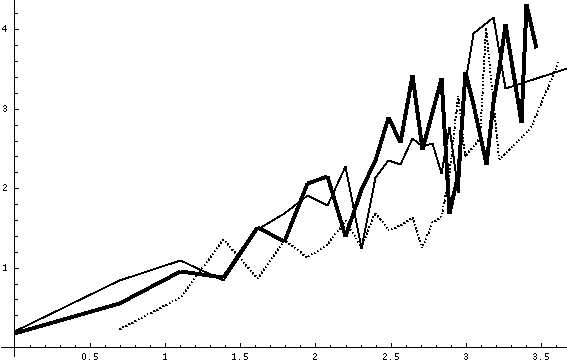
Figure 8: Log of geometric mean of number of tries before correct
interpretation was found versus log of sentence length.
Dotted line is first training set, heavy line is second,
and thin line is third.
1 pacific ranges and facilities department, sled tracks.
2 airms, pointer and stabilization subsystem characteristics.
3 vacuum chamber in operation in laser damage facility.
4 early fleet training aid: sidewinder 1 guidance section cutaway.
5 awaiting restoration: explorer satellite model at artifact storage facility.
6 fae i (cbu-72), one of china lake's family of fuel-air explosive weapons.
7 wide-band radar signature testing of a submarine communications mast in the
bistatic anechoic chamber.
8 the illuminating antenna is located low on the vertical tower structure
and the receiving antenna is located near the top.
Figure 9: Example sentences.
Sent. Training Final No binary No unary
number Time Tries Time Tries Time Tries Time Tries
1 27.07 13 17.93 5 8.27 5 60.63 19
2 70.27 10 48.77 9 94.62 14 124.9 23
3 163.0 19 113.1 19 202.9 23 2569.0 22
4 155.2 9 96.07 3 63.95 8 229.3 22
5 86.42 8 41.02 3 49.48 6 130.6 30
6 299.3 11 65.78 7 68.08 5 300.4 15
7 1624.0 24 116.5 5 646.0 12 979.3 25
8 7825.0 28 35.02 2 35.60 3 >50000-
Figure 10: Parse CPU time and number of tries until the best
interpretation is found for the eight example sentences.
Go to paper index