
A key obstacle to accessing images on the information superhighway is some necessary content analysis. Captions help, but they cannot supplant some necessary image processing. We discuss how image processing is more a bottleneck than it may at first appear. To do it adequately for the wide range of pictures that could occur in a picture library requires additional computational support in the form of "information filters", or redundant but fast processing to eliminate obvious poor matches, and we discuss some of what is required.
Much of the literature on integrating natural language processing and visual processing does not address, in my view, the fundamental problem in the integration. That is wide variation in processing requirements (time and space) of the two types of information. This is more than a problem in engineering of systems, but a fundamental conceptual problem, because it makes relaxation algorithms nearly impossible and prevents true integration of reasoning. But awareness of the problem is not widespread since it can only be seen when we move away from artificial problems to look at real-world applications. (Research that does address the problem includes (Srihari, 1994) and (Barber et al, 1994).)
Consider the natural-language processing. When natural language refers to visual phenomena, it is concrete and not too problematic to parse except for the problem of word sense disambiguation. Ten-word or twenty-word sentences are common, requiring maybe 100 bytes to store. A wide range of parsing methods can handle this sort of input adequately, and need not require much time to come up with reasonable parses. Statistical parsing may require big databases, but retrievals from those database are relatively few per sentence, and can be designed to be quite efficient. Thus 1-second parsing times are common on Sun workstations or equivalents. If you prefer statistical parsing, the most useful statistical information is just word-sense frequencies, which requires on the order of 100,000 entries for a broad coverage of English, each a few bytes, which is not much.
Consider the visual processing. Any useful picture is going to require at least the resolution of a television picture, or say 0.5 million pixels of one byte each. But without special hardware, early visual processing requires at least ten microseconds per pixel, for 5 seconds just for preprocessing. Then any useful further processing is going to need to characterize the shapes (Kato, 1992; Rabitti and Savino, 1992), which requires at least an additional pass through the pixels to compute things like brightness, color, texture, edge smoothness, right angles in the boundaries, and general region characterization (because we cannot compute statistics until we know the sets to which they apply). So we are up to 10 seconds as a minimum, and we have not yet considered time-consuming higher-level methods like relaxation that interrelate regions of the picture and apply a wide variety of constraints. So it appears that visual processing must be at least 100 times more time-consuming than language processing. By this line of analysis, there appears no need to do research on the interaction of natural language and vision, because vision is the key problem, and vision will drive natural-language processing.
One rejoinder to this is to look at human brains, where much of the visual processing uses special-purpose highly-parallel neuralware, while language processing does not seem to require much neuralware. Apparently this helps balance visual processing and language processing. But this is not reasonable solution for artificial intelligence. Attempts to use general-purpose parallel machines like the Connection Machine for artificial intelligence have not gone well. Also, the relating of vision and natural language would seem intuitively to be something that does not require as much computational power as some of the other methods of artificial intelligence like theorem-proving and learning, as deep analysis of two knowledge representations is not necessary to relate them.
This phenomenon is not much affected by doing the visual processing in advance, because then it is likely that natural-language information is also available in advance, and its processing can be done then too. Advance visual processing will produce considerably more data than the natural-language processing, since if it does not know what its data is to be used for, it should describe each picture region carefully and give its interrelations with each other region. So there still will be much more visual processing to do, only at a higher level , than natural-language processing. Some of it will involve solving a subgraph isomorphism problem, which in general is NP-complete, since the visual semantic network must eventually be matched to and integrated with the natural-language semantic network
Another proposed solution is to go for domain-dependent visual processing much like expert systems for particular visual tasks; such processing could be significantly faster for the same level of accuracy. Examples of this approach are the schema-based approach of (Draper et al, 1989) and the context-dependent approach of (Strat, 1992). But our main interest is in skimming visual information for which such analysis may not be necessary.
We are exploring these issues in the context of the MARIE system for retrieval of pictures from a picture library based on an English description of what a user is looking for (Rowe and Guglielmo, 1993; Rowe, 1994b; Rowe, 1995a).). MARIE is designed to exploit the results of preanalysis of both the caption (parsing) and the picture (image processing), although most of our previous work has been on the parser. This preanalysis will result in predicate-calculus descriptions of the caption (plus the accompanying formatted registration information), i.e., its parsing, and of the shapes in the picture, i.e. a statistical summary of the two-dimensional region segmentation. A user inputs a description in English of what they want, which is parsed to a predicate calculus description, and then matched to the stored predicate-calculus descriptions for each picture. Matching is a check of subgraph isomorphism, and successful matches are returned unranked.
As an example, consider the photograph below from the MARIE testbed, the library of the naval air test facility NAWC-WD at China Lake, California. This photograph and its caption are typical of the older black-and-white photographs in the library. The caption is:
00124: facilities at harvey field. view of runway with aircraft from inside tower. personnel working.
Note the caption sentences are short, something typical of the technical applications where the greatest payoffs for integrating natural language and vision will be. And the words have relatively straightforward semantics, even "harvey" which can be interpreted as a name that need not be retrieved from the lexicon since it comes before the special name-suffixing word "field". Thus natural-language processing of this caption will not be too hard (more discussion of this is in (Rowe, 1994a). And this caption is quite typical of technical photographs: There's not much more to be said about this photograph that a viewer couldn't see more easily for themselves in the accompanying photograph; the caption contributes only the necessary non-visual information.
We digitized the corresponding black-and-white photograph and reduced it to 107x86 pixels, with the result shown below. We believe in general that a reduction to approximately 100x100 pixels is necessary for pictures in large picture libraries to economize on space. Usually the highest-priority activity with picture libraries is finding relevant picture for which high resolution is not necessary. A 100x100 pixel image we have found by experiment to be a reasonable compromise between image processing time and picture quality. The quality of reproduction for a fixed number of image bits can be improved by dithering (alternating between colors in a single-color region), which we have found helpful in our project.
On other hand, visual processing for this photograph faces difficult problems. The figure below shows typical results of a first attempt at region segmentation for this picture using our own image-processing software (Rowe, 1995a), assuming good guesses for region-merging thresholds. The numbers and letters represent region codes; the first six rows were omitted. The linguistic subjects, following the linguistic heuristics of (Rowe, 1994b), are the runway, aircraft, and personnel. But the runway cannot be clearly delineated because only some of its outline is visible, with hazy boundaries; the aircraft are so far away and bleached out that they are quite difficult to identify; and the outlines of the personnel cross the boundary of the picture and they are in a several quite different configurations, making identification difficult. In addition, the vertical separators of the windows appear to make separate regions out of the runway, and the rectangular shape of the windows can be misidentified as many other rectangular objects. Of course, subsequent more sophisticated processing could solve these problems, but it would take time.

As another black-and-white example, consider:
178012: `Roseville incident. SCO-96 MK 81 bomb electric heat cookoff test 454692. view of bomb wrapped. view of wires attached to bomb. pretest view.'
Here "Roseville incident" is a supercaption describing a class of pictures about safety testing of munitions storage. The bomb and wires are the only depictable grammatical subjects and can be inferred to be depicted in full.

And here is the region segmentation using standard split-and-merge methods based on local decisions. Clearly some additional segmentation must be done at inflection points in order to separate the black portion of the bomb from its shadow, and collinearity should be used to infer the segmentation of the black portion with the white portion. We are exploring inclusion of information from the Hough transform to infer boundaries along multicolored regions like the missile. But segmentation inferences in general can be quite domain-dependent, and would not apply, say, to pictures of plants where many spurious inflection points and collinearities of edges would occur.
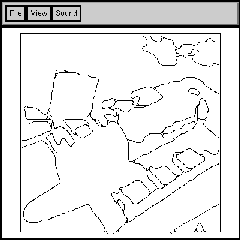
Are these examples typical of the problems facing the integration of natural language and vision? Unfortunately, we believe not. Certainly, there are valuable special cases that are easier to handle, like face extraction from newspaper photographs and vehicle extraction from aerial photographs, for which complete success may be soon possible. But with the development of the "information superhighway", we believe that the most important need is for management of libraries of large numbers of unrestricted photographs. If we can make progress on the general problem, we can make a big impact.
We argue that the key concept missing is redundant visual processing in the form of "information filters". That is, methods to provide quicker but incomplete analysis of visual information so as to give natural-language processing something to work with. These information filters would not replace full visual processing, nor even possibly contribute to it, but would be intended to quickly rule out inappropriate visual matches based on quick linguistic processing like keyword extraction. An example filter for captioned pictures would be a process that checks whether there is a large (10% to 50% of the picture) light-colored object near (with center of gravity within 5% of picture length of) the center of a picture, which would be helpful to the interpretation of a natural-language expression with a grammatical subject that is known to be visible. This would be used whenever the caption mentions a kind of portable equipment as the primary subject of the picture, and the rationale would be that picture subjects tend to be centered and light in color. Even if heuristics do not always work, they can still be useful if they rule out large numbers of irrelevant pictures.
MARIE-1, the first implementation of MARIE, used several information filters to improve processing speed as described in (Rowe, 1995b). First, a quick "coarse-grain" filter was used first to rule out pictures that did not mention any of the words in the user query or their superconcepts. Second, a registration-data filter ran a conventional SQL query on any information likely to be helpful from the formatted data for the pictures. Third, pictures were classified into types (like test pictures and public-relations pictures) and pictures incompatible with the possible types of the query were ruled out. These three filters were very helpful in reducing the number of picture descriptions that needed to be compared to answer a user query.
To be more formal about the advantages of filtering, we need some mathematics. Let c be the query processing time for full visual processing of a single picture, d the processing time of the quick check of the picture, p the probability of a picture passing the quick check, and n be the number of pictures to check. Then if the quick check is perfect and never rules out any relevant pictures, it will be desirable if nd + pnc < nc, which simplifies to d/(1-p) < c; and (Rowe, 19945b) develops generalizations of this result. On the other hand, suppose the quick check is not perfect and does rule out some fraction q of the relevant data, but the user agrees that saving some amount of time T is justification for that q; typically for small values of q, T is a linear function of it with some user-specific constant of proportionality k. Then the quick check is still desirable if nd + pnc + qk < nc, or (d+(qk/n))/(1-p) < c. This inequality can be checked for any proposed information filter to see if it is worthwhile. A filter that seems worthwhile can then be included in the cost c.
Some examples of useful information filters that could be invoked when appropriate words are present in the natural language are:
1. A filter that rules out dark pictures when the natural language describes daytime and outdoors locations;
2. A filter that rules out pictures with many bright colors when the natural language describes industrial equipment;
3. A filter that rules out pictures without sharp right angles when the natural language describes buildings;
4. A filter that rules out pictures without face-like shapes when the natural language describes people.
Filters can also be written for matches of individual picture regions and region clusters to individual noun phrases in a natural-language description, like:
5. A filter that requires that airplanes have at least four bumps.
6. A filter that requires that sky touches an edge of the picture.
7. A filter that requires that sky not enclose a building.
A rule-based expert system containing such filters could be constructed, where each rule would map to a filter implementation. Experts could be people who do considerable searching through picture collections, like the NAWC-WD Photo Lab personnel we have talked to on the MARIE project. Many of the rules involved, like those above, are pretty domain-independent; other rules could be generalized to make them more domain-independent, like generalizing the second rule above to more kinds of equipment.
This is a domain for which thousands of rules can be developed. With such a big rule-based expert system for information filtering, the order of application of filters is critical to efficiency. Further analysis can be done if we take a to be the processing time per picture of filter 1, b to be the processing time per picture of filter 2, p to be the probability of success of filter 1, and q to be the probability of success of filter 2. Then it is better to do filter 1 first then filter 2 rather than vice versa if a + pb < b + qa or if a/(1-p) < b/(1-b). This can be used as a sorting criterion for filter order if probabilities are independent, and can used in a more complex way otherwise, as described in (Rowe, 1995b). Filter insertion or deletion can also be mathematically analyzed, as described there.
Would a more connectionist approach be preferable? Maybe, but there are so many possible descriptors of a picture that it would be hard to evolve towards picking the correct ones to associate with a given conclusion. Connectionist approaches work better for a small set of inputs that are related in some complicated way. Instead, human experts seem necessary to supply some of the complex semantics of the real world. So good integration of natural language and vision may turn out to be quite knowledge-based.
Would parallel processing of filters help? Surprisingly, not often. Suppose we have R processors available. We can show that it never makes sense to execute different information filters in parallel, making the reasonable assumption that the cost of parallelizing is a fixed overhead and the speedup from parallelizing is proportional to the number of processors.
Data -Parallelism Theorem: Suppose the cost of implementing two information filters in parallel for a set of data items is kR + max(c1/r1, c2/r2) where k is a constant, R is the number of available processors, ri is the number of processors allocated to filter i, and ci is the total execution cost for filter i. Then it never is more efficient to do the two in parallel than in sequence. Proof: The cost of doing the filters in sequence (using first all R processors for the first filter, then all R for the second filter) is either (c1/R) + (p1c2/R) or (c2/R) + (p2c1/R) where pi is the probability of success of filter i. The cost of doing them in parallel is kR + max(c1/r1,c2/(R-r1)). The minimum of this with respect to r1 occurs with perfect load balancing (if it is possible) of the two processors, or when c1/r1 = c2/(R-r1) or when r1 = Rc1/(c1+c2). Then the cost becomes kR + ((c1+c2)/R) = kR + (c1/R) + (c2/R). Comparing this to the terms of the cost of the filter sequence with filter 1 first, we see kR > 0, c1/R = c1/R, and c2/R > p1c2/R. Hence the parallel-filter cost is always greater. Similarly for the filter sequence with filter 2 first, kR > 0, c2/R = c2/R, and p2c1/R > c1/R, and hence the parallel-filter cost is always greater. QED.
This theorem says that data parallelism, where all processors work on the same filter at the same time, is preferable to filter parallelism when multiple processors are available. Hence we should concentrate instead on trying to select and sequence the filters appropriate for a given task.
R. Barber, M. Flickner, J. Hafner, W. Niblack, D. Petkovic, W. Equitz, and C. Faloutsos. Efficient and effective querying by image content. Journal of Intelligent Information Systems, 3, 3-4 (July 1994), 231-262.
B. Draper, R. Collins, J. Brolio, A. Hanson, and E. Riseman. The Schema system. International Journal of Computer Vision, 2 (1989), 209-250.
T. Kato. Database architecture for content-based image retrieval. SPIE: Image Storage and Retrieval Systems, San Jose, CA, February 1992, 112-123.
F. Rabitti and P. Savino. Automatic image indexation to support content-based retrieval. Information Processing and Management, 28, 5 (1992), 547-565.
R. K. Srihari. Use of collateral text in understanding photos. Artificial Intelligence Review, 8, 5-6, 1994-1995.
N. C. Rowe and E. J. Guglielmo, Exploiting captions in retrieval of multimedia data. Information Processing and Management, 29, 4 (1993), 453-461.
N. C. Rowe, Statistical versus symbolic parsing for captioned-information retrieval. Proceedings of the ACL Workshop on Combining Symbolic and Statistical Approaches to Language, Las Cruces, NM, July 1994. [Rowe, 1994a]
N. C. Rowe, Inferring depictions in natural-language captions for efficient access to picture data. Information Processing and Management, 30, 3 (1994), 379-388. [Rowe, 1994b]
N. C. Rowe, Retrieving captioned pictures using statistical correlations and a theory of caption-picture co-reference. Fourth Annual Symposium on Document Analysis and Retrieval, Las Vegas, NV, April 1995. [Rowe, 1995a]
N. C. Rowe, Using local optimality criteria for efficient information retrieval with redundant information filters. ACM Transactions on Information Systems, July 1996. [Rowe, 1995b]
T. Strat. Natural object recognition. New York: Springer-Verlag, 1992.
This paper appeared in the 1995 Fall AAAI Symposium, Computational Models for Integrating Natural Language and Vision, Cambridge MA, USA, November 1995, 102-106.