A Model of
Deception during Cyber-Attacks
on Information Systems
Neil C. Rowe
Dept. of Computer Science, U.S. Naval Postgraduate School
Monterey, California, USA
ncrowe@nps.edu
Abstract
Deception
is a classic technique useful for military operations. With information systems around the world
under frequent attack every day, it is appropriate to consider analogies from
conventional warfare, and deception has historically been powerful as both a
tactic and a strategy. We here
systematically enumerate and rank the available deception options for
information systems, both offensively and defensively. We then consider how defensive deceptions
can be packaged within "generic excuses" that will more convincing to
an attacker than isolated refusals to obey commands. We describe how the selection of the best generic excuses and
excuse application times can be formulated with probabilities as an
optimization problem and solved. Our
theory lends itself well to computer implementation and we provide several
examples.
This paper
appeared in the IEEE First Symposium on Multi-Agent Security and Survivability,
Philadelphia, August 2004.
Keywords
deception, information security,
security and privacy protection, human communications, lying, multiagent
systems, Bayesian inference, excuses
INTRODUCTION
Deception is an important two-agent psychological phenomenon
with many applications to information security. Deception can occur offensively, as when attackers try to fool
our information systems into giving away secrets or destroying themselves, or
it can occur defensively, as when a computer pretends by exaggerated processing
delays to succumb to a denial-of-service attack so the attacker goes away. Little systematic analysis has been paid to
the concept of deception in information systems, however. Most writers assume methods of deception are
intuitively obvious or comprise only a few categories. But there are many possible kinds of
deception, some quite subtle. And
deceptions can be automated. So it is
important in defense of our information systems that we develop a better theory
of deception and ways to translate it into security practices.
Our main interest is in using deception to defend
information systems, as a second line of defense when access controls have been
breached on those systems. Over a thousand
attack methods a year are being reported to the Carnegie-Mellon Computer
Emergency Response Team and they are increasing in sophistication [21]. Deception can be highly effective against
these attacks since information systems are thought to be totally honest. For instance, when asked to download a
suspicious file, a deceptive operating system could say the network isn't
working, or could pretend to download it, or could download it and delete later
when the attacker isn't checking. It
may take an attacker a while to realize they are being deceived. This time may be critical in
denial-of-service attacks and "information warfare" when the attacker
depends on surprise. But we need a
framework for proposing deceptive practices in defense of information systems
because there are so many options to consider.
Such a framework must also model deceptions that attackers use so we can
find good counter-deceptions to foil them.
We could implement defensive deceptions in modified operating systems.
Is this kind of deception ethical? The ethics of deception have been much
debated over the centuries [6]. But
there are cases in which it is generally justified, as when the costs of no
deception are much more severe than the costs of deception. This can be argued is true for a computer
system where to allow an attack can make it inoperable with worthless data; provided our deceptions are carefully enough triggered to rarely catch
legitimate users. So we will proceed here
on the assumption that a broad range of deceptions can be ethical in defending
our information systems against serious attacks.
What about automated attacks and script-following
("script kiddie") attacks?
Deception would seem to need a thinking person to fool. We believe it more valuable for security
analysis to focus on assaults on important computer systems where attackers are
thinking carefully about what they are doing.
Nonetheless, automated and semi-automated attacks are easily tripped up
by small surprises like unexpectedly absent resources. Most of the deceptions we will enumerate
here are surprises in some sense and thus will also foil automated and
semi-automated attacks.
To illustrate the issues, consider a Web service we
have implemented. If users to our
"demos" site click on a link saying "Secret file directory
access" they see a typical-looking file directory (Figure 1, upper
right). If they click on
"org.htm" they see an organization chart with unexplained acronyms
(lower right). If they examine several
of these files, they see what appears to be encrypted data (upper left). If they try to open "/root/sigs/
bio_weber/~thornton/13Hands," they get the message "Error 401: No
detailed message"; if they try "/root/sigs/bio_weber/leaver/
1000m/panel.cry," they get
"You are not authorized to view this page"; and if they try
"/root/sigs/bio_weber/ module6.rzp," the program waits ten minutes
and then says the page is too large to display. Other images shown for this directory include pictures of someone
under "bio_weber" (apparently Mr. Weber), wood grain, a blurry
picture of someone holding what appears to be a toy blimp, PowerPoint slides
about wireless LANs, an Iraqi missile launcher, a strange experimental vehicle
being loaded by crane on a ship (lower left in Figure 1), an explosion cloud,
and a graphic labeled "Mishap Plans" (under /root/sigs/bio
web/leaver/1000m/Images/Now is the time_ files/avsafety/gouge. It looks like information about some
military organization where Mr. Weber is the founder and Thornton and Leaver
are current employees engaged in something involving sinister secret networked
weapons that gouge things, whose shortly imminent use ("now is the
time") is intended to look accidental (a "mishap").
This is a prototype of a new kind of
"honeypot" designed to attract spies and waste their time. Information derived from real data is put together
randomly to encourage the human tendency to see patterns where none exist. The behavior is generated by a Java servlet;
there are no files and directories except for one big file of images, captions,
and Web page names extracted by a crawler from easily accessible military Web
pages. The page names are used to
randomly create reasonable-sounding directory and subdirectory names, with
random extensions added to the file names.
Those with "htm" extensions mostly pull related image-caption
pairs from the database. Those with
other extensions create different kinds of random data (from a pseudorandom
seed that is a function of the file size to ensure consistency). The system exaggerates loading delays of the
fake files, and if the imaginary file is listed as especially large, the user
is told the file is too large to load after a long wait. Randomly 10% of the time the user is told
that they do not have authorization to view a file (with two kinds of error messages). All in all, the site is designed to make a
spy think there are secrets here and to see nonexistent connections, a classic
way to neutralize spying agencies as was done to U.S. CIA counterintelligence
during the 1970s. It could also
frustrate legitimate users but legitimate users should not be looking for
secrets. This deceptive software was
carefully crafted; a question is whether design of similar deceptive software
could be automated.
Surprisingly, not much work has addressed the idea
of deception in defense of computer systems.
Some good work has developed honeypot computers and
"honeynets," computer systems and networks whose purpose is to entrap
attackers to obtain information about their attack methods [18]; these are a
simple passive form of deception. [1]
suggests a general approach to planning defenses automatically in adversarial
situations, including classic military tactics like deception; [8] suggests ways
to encourage maladaptive behavior in enemy organizations. [10] and [19] provide ideas for modeling
attacks on computer systems, the former suggesting some interesting ideas about
deception in defense. Work on
multi-agent systems is starting to examine societies of deceptive agents [3, 9,
30].

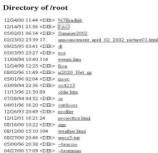

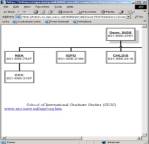
Figure 1: Example screens from the honeypot.
A TAXONOMY OF DECEPTION METHODS IN ATTACKS ON INFORMATION SYSTEMS
[4] identifies six basic methods of deception:
masking, repackaging, dazzling, mimicking, inventing, and decoying. These are good at identifying categories of
effect but do not explain how deception occurs. [31] suggests nine basic "misperception" categories:
pattern, players, intention, payoff, place, time, strength, style, and
channel. These are a good start at a
taxonomy but fail to incorporate important semantic distinctions developed over
the years in artificial intelligence.
Work in military science often refers to deception: [13] proposes nine
methods of military deception but these are specific to military operations;
[16] provides six useful principles of military deception, but no theory. [17] provides some useful pieces of a
theory, but the concern is analysis of deception rather than generation of deception.
A deeper theory of deception can be developed from semantic
cases of computational linguistics [14].
Every action can be associated with other concepts called semantic
cases, a generalization of syntactic cases in language. Various cases have been proposed, of which
[11] is the most comprehensive we have seen.
To their 28 we add four more, the upward type-supertype and part-whole
links and two speech-act conditions [2], to get 32 altogether:
·
essence: supertype (generalization of the action type)
and whole (of which the action is a part)
·
participant: agent (the person who initiates the
action), object (what the action is done to), beneficiary (the person who
benefits), experiences (the psychological feature associated with the action),
instrument (some thing that helps accomplish the action), accompaniment (additional object associated
with the action) and recipient (the person who receives the action)
·
space: location-at, location-from, location-to,
location-through (through which the action occurs), direction (of the action),
and orientation (in a metric space)
·
time: frequency (of occurrence), time-at, time-from,
time-to, and time-through
·
causality: cause, contradiction (what this action contradicts
if anything), effect, and purpose
·
speech-act theory: precondition (on the action) and
ability (of the agent to perform the action)
·
quality: content (type of the action object), manner
(the way in which the action is done), material (the atomic units out of which
the action is composed), measure (the quantity associated with the action),
order (of events), and value (the data transmitted by the action)
Our claim is that deception operates on an action to
change its perceived case values. For
instance, an attacker masquerading as the administrator of a computer system is
concealing the agent case and purpose case associated with their actions on
that system. For the fake-directory
prototype that we built, we use deception in object (it isn't a real directory
interface), "time-through" (some responses are deliberately delayed),
cause (it lies about files being too big to load), preconditions (it lies about
necessary authorization), and effect (it lies about existence of files).
Not all the cases make sense for the interaction
between an attacker and the software of a computer system. We can rule out beneficiary (the attacker is
the assumed beneficiary of all activity), experiences (psychological states
don't matter in giving commands and obeying them), recipient (there are only
two agents), "location-at" (you can't "inhabit" cyberspace),
orientation (there is no coordinate system in cyberspace),
"time-from" (attacks happen anytime), "time-to" (attacks
happen anytime), contradiction (commands don't include comparisons), manner
(there's only one way commands execute besides in duration), material (everything
is bits in cyberspace), and order (the order of commands or files rarely can be
varied).
In general, offensive opportunities for deception
are as frequent as defensive opportunities, but appropriate methods
differ. For instance, the instrument
case is associated with offensive deceptions in cyberspace since the attacker
can attack with a variety of methods: buffer overflows, viruses, backdoors,
stolen passwords, etc. The defender has
few defensive instruments and must focus on foiling the attacker's. In contrast, "time-through" is
primarily associated with defensive deceptions in cyberspace since the
defending system controls the time it takes to respond to a command, and is
little affected by the time it takes an attacker to issue commands to it. But "object" can be associated
with both offense and defense because attackers can choose to attack
little-defended targets like unused ports, while defenders can substitute
low-value targets like honeypots for high-value targets that the attacker
thinks they are compromising. Table 1
summarizes the suitability of the remaining 21 deception methods as we judge
them on general principles. 10
indicates the most suitable, and 0 indicates unsuitable. These numbers were obtained by expert-systems
methodology and could be refined by surveys of users or deception
experiments. This table provides a
wide-ranging menu of choices for deception planners.
Table 1 specializes an artificial-intelligence
planning-based approach in which deceptions at a state can be represented as
sets of atomic "ploys" of three kinds: Deletion of facts from the
state, addition of facts to the state, or change of facts in the state. For instance, if we want to prevent an attacker
from downloading a suspicious file, giving a "network is down" excuse
amounts to an addition of a network-status fact to the state and deletion of
the expected download from the state.
But this is clearly too limited a model since the manner in which information is conveyed by a deceiver is just as
important as the content of the deception. For instance, a command can be refused by a
system, to the same effect, by one of these "ploy presentation
tactics":
·
Pretend that the attacker's command is not legal
syntax.
·
Give a false excuse to the attacker why the command cannot
be done:
·
Say that a necessary resource (network, file system,
directory, etc.) is unavailable.
·
Say that authorization is required for a necessary resource.
·
Claim this is the wrong command for the resource.
·
Lie that the command has been done.
·
Obey the command now, but undo it later when the
attacker is not looking.
·
Take such a long time to do the command that the attacker
gives up.
·
Distract the attacker with so much extraneous information
and so many requests that they give up.
·
Secretly transfer the attacker to a "safe
sandbox" where their commands will be harmless.
·
Secretly transfer "spyware" back to the
attacker's machine so you can trace them and stop them.
Choosing the ploy presentation tactic will be
another key part of a deception strategy.
Table 1:
Evaluation of deception methods in cyberspace.
|
Deception
method
|
Suitability
for offense in information systems, with general example
|
Suitability
for defense in information systems, with general example
|
|
supertype
|
6 (pretend attack is something else)
|
0
|
|
whole
|
8 (conceal attack in a common sequence of
commands)
|
0
|
|
agent
|
4 (pretend attacker is legitimate user or is
standard software)
|
0
|
|
object
|
8 (attack unexpected software or feature of a
system)
|
5 (camouflage key targets or make them look
unimportant, or disguise software as different software)
|
|
instrument
|
7 (attack with a surprising tool)
|
0
|
|
accompaniment
|
9 (a Trojan horse installed on a system)
|
6 (software with a Trojan horse that is sent to
attacker)
|
|
location-from
|
5 (attack from a surprise site)
|
2 (try to frighten attacker with false messages
from authorities)
|
|
location-to
|
3 (attack an unexpected site or port if there are
any)
|
6 (transfer control to a safer machine, as on a
honeynet)
|
|
location-through
|
3 (attack through another site)
|
0
|
|
direction
|
2 (attack backward to site of a user)
|
4 (transfer Trojan horses back to attacker)
|
|
frequency
|
10 (swamp a resource with tasks)
|
8 (swamp attacker with messages or requests)
|
|
time-at
|
5 (put false times in event records)
|
2 (associate false times with files)
|
|
time-through
|
1 (delay during attack to make it look as if
attack was aborted)
|
8 (delay in processing commands)
|
|
cause
|
1 (doesn't matter much)
|
9 (lie that you can't do something, or do
something not asked for)
|
|
effect
|
3 (lie as to what a command does)
|
10 (lie as to what a command did)
|
|
precondition
|
5 (give impossible commands)
|
8 (give false excuses for being unable to do something)
|
|
ability
|
2 (pretend to be an inept attacker or have inept attack
tools)
|
5 (pretend to be an inept defender or have easy-to-subvert
software)
|
|
content
|
6 (redefine executables; give false file-type
information)
|
7 (redefine executables; give false file-type
information)
|
|
measure
|
5 (send data too large to easily handle)
|
7 (send data too large or requests too hard to attacker)
|
|
value
|
3 (give arguments to commands that have unexpected
consequences)
|
9 (systematically misunderstand attacker commands)
|
MODELING TRUST IN DECEPTIONS
Our goal is to provide "counterdeception"
for defending information systems, planning to foil an attacker's deceptions
with deceptions of our own. (Attackers
could use an analogous approach to improve their attacks.) Besides the intrinsic suitability of a
deception, we must also consider how likely it fools an attacker.
Our estimation that a deception succeeds assumes it
is a monotonically decreasing function of the a priori probability of the
deceptive action occurring without deception.
Humans who are trained to detect lies look for inconsistencies and
improbabilities [15], a form of this principle. Probabilities can be estimated from statistics of how often
events occurred in a normally operating computer system, e.g. how many times
the network connection was down on the average. We can use a sigmoid-shaped function as in neural-network methods
for similar situations, a function that is near-flat at both ends but increases
from 0 to 1 in the middle of its range.
[12] and [3] provide interesting alternative models.
The Strength of Attacker Hypotheses
We need a model of "suspiciousness" or
lack of trust by an attacker in an information system, since this is what we
want to manage carefully when we are deceiving an attacker. Some modern research in sociology on the
concept of trust provides analysis that we can use. [27] claims "trust is a bet about the future contingent
actions of others." Let us
represent it as trust(A,D,O,C) which means the probability that attacker A
believes defender D (the computer system) will perform order O under condition
C.
Though [27] did not formulate this mathematically,
this approach is compatible with Bayes'
Rule, which says p(T|E) = p(E|T) p(T) / p(E) where T is the act of trust is
subsequently justified by events for a particular attacker A, defender D, order
O, and conditions C, and E is some piece of evidence that D provides as to
their trustworthiness (like obeying the last command promptly). When we have several pieces of evidence E1,
E2, etc. the formula becomes:
p(T|E1&E2&E3&...) =
p(E1&E2&E3&...|T) p(T) / p(E1&E2&E3&...)
If the evidence arrives sequentially, we can write
this as:
p(T|E1&E2&E3&...) = p(T) (p(E1|T)/ p(E1)) (p(E2|T&E1)/p(E2|E1))
(p(E3|T&E1&E2)/p(E3|E2&E1))...
When some of the evidence is independent, we can
eliminate some of the conjuncts; if all the evidence is independent, we get the
"Naive Bayes" formula [32]:
(p(E1|T)/p(E1)) (p(E2|T)/p(E2)) (p(E3|T)/p(E3) ...
p(T)
These last two forms conveniently separate each
piece of evidence. Each of these ratios
can be greater than 1 (for evidence increasing trust, such as the compliance of
D with commands) or less than 1 (for evidence decreasing trust, such as refusal
of D to comply with commands).
The main difficulty in applying this formula is not
so much that independence does not apply (the formula has been shown to be a
useful ranking method in many applications when independence clearly does not
hold), but that we rarely have sufficient statistics on the exact situation of
interest. If A has not dealt with D
before, or A has not dealt with D in regard to either O or C, A must estimate
probabilities. [9] notes this in
modeling deception and tries a different approach, but we do not see this is
necessary since one can use the results of a running intrusion-detection system
if enough data has been collected about a user, and otherwise "statistical
inheritance" with known marginal statistics on generalizations D' of D, O'
of O, and C' of C. If there is more
than one such D', O', or C' we need to take a weighted average of their
predictions, where typically the weight is the inverse of the corresponding set
size (the number of things in the real world to which the class corresponds,
since larger classes are further in properties from the target class). Such reasoning can be fallacious, as for
instance when we have had one bad experience with a Microsoft product and we
generalize to all Microsoft products, or when we have had one bad experience
with a person of one ethnic group and we generalize to all members of that
group. Nonetheless, such reasoning is
essential for everyday situations. So
we can assume D is a typical Internet site, or O is a typical network-using
command, and use trust in all sites or all network commands for our
estimate. [27] enumerates a comprehensive
set of such inferences; for cyberspace, these should include influences from
what attacker A hears from other hackers or the general trust level of the
hacker "society."
Generic Excuses for Deception
There are several kinds of trust, however, because
deception is not the only hypothesis that an attacker may entertain as we
attempt to deceive them. A well-known
psychological trait of humans is their ability to see patterns. So rather than just trying to conceal a
deception, it is usually easier to convince an attacker of some different explanation of events.
Magicians often try to induce such explanations in audience, like
"supernatural visitation," "psychic powers," or "new
laws of physics," also called "mock explanations" [23]. Some good such "generic excuses"
in responding to information-systems attacks are:
·
The system, file system, or network has crashed.
·
Attacker actions "broke" something on the
system or network so it is not working.
·
Testing is being done on the system or network.
·
Particular software on the system or network is new and
not fully debugged.
·
Network communication defaults are incorrect.
·
Security policy or limits have recently changed on the
system or network, affecting user capabilities.
·
The system or network has been "hacked" and
compromised.
·
A practical joker [26] is deliberately trying to
irritate users.
To these we must add the generic excuse of
"deception," the one hypothesis we do not want the attacker to
entertain. We can assign a priori
probabilities to the generic excuses.
These will vary with the system and its setting, but let us assume here
typical values with "network down" of relative likelihood 0.10,
"testing" 0.10, "bugs" 0.08, "communications
faulty" 0.06, "policy change" 0.04, "hacked" 0.01,
"practical joker" 0.01, and "deception" 0.01. Generic excuses should only be given when we
are reasonably certain that the user is an attacker.; see below under "The
Suspiciousness of the Attacker" and "The Penalty for Deceiving
Non-Attackers."
As an illustration, suppose an attacker of a
computer system tries to download a file from their home site and gets the
error message "no network response"; then they manually modify an
operating-system executable and get the message "error in file
routines." Suppose the a priori
probabilities of the message "no network response" is 0.02 and
"error in file routines" are 0.06.
Suppose the probability of a network error occurring when the network is
down is 0.9, the probability of file error when there are bugs in the system is
0.8, and the probabilities of vice versa are 0.01 each. Suppose the probability of any message given
deception is 0.1. Suppose the message
"no network response" occurs 20% of the time when there are network
problems, and "error in file routines" appears 50% of the time when
there is a file error. Then by
statistical inheritance which assumes the error messages are representative of
their classes, the probability of "no network response" when the
network is down is 0.9*0.2 = 0.18, and the probability of "error in file
routines" when there are bugs in the system is 0.8*0.5 = 0.4, the
probability of "no network response" when there are bugs in the
system is 0.01*0.2 = 0.002, and the probability of "error in file
routines" when the network is down is 0.01*0.5 = 0.005.
Then with a Naive Bayes approach, we can calculate
the likelihoods of the three hypotheses "network is down," "bugs
in the system," and "deception" after the download attempt as
0.10*0.18/0.02 = 0.9, 0.08*0.01/0.02 = 0.04, and 0.01*0.1/0.02 = 0.05. We calculate likelihoods after the attempted
modification of the executable as 0.9*0.005/0.06 = 0.075, 0.04*0.4/0.06 =
0.267, and 0.05*0.1/0.06 = 0.083. So
the contradictory clues have the effect of making deception more plausible than
the other hypotheses even though its initial likelihood is low.
Connecting Generic Excuses with Deception Methods
These generic excuses differ in their compatibility
with the defensive deception methods we enumerated in Table 1. We can summarize compatibility in Table 2,
where 0 means incompatible, 5 means indifferent, and 10 means compatible. Compatibility includes both logical preconditions
(network excuses only work for network actions) and statistical tendencies
(hackers aren't usually concerned about redirecting your commands). Again, these were obtained by expert-systems
methodology and reflect the degree to which the deceptive act could be caused
by the excuse.
Table 2: Compatibility of deception
methods with generic excuses.
|
Hypothesis /
Deception
|
Net
down
|
Test
|
Bugs
|
Comms
faulty
|
Policy
change
|
Hacked
|
Joker
|
Deception
|
|
object
|
0
|
3
|
3
|
0
|
6
|
8
|
8
|
10
|
|
location-from
|
0
|
5
|
2
|
0
|
5
|
8
|
6
|
5
|
|
location-to
|
0
|
7
|
5
|
0
|
5
|
8
|
8
|
10
|
|
direction
|
0
|
0
|
3
|
0
|
0
|
8
|
5
|
5
|
|
frequency
|
8
|
10
|
8
|
8
|
4
|
1
|
5
|
1
|
|
time-at
|
0
|
8
|
2
|
2
|
0
|
8
|
2
|
5
|
|
time-through
|
0
|
8
|
5
|
8
|
5
|
8
|
8
|
8
|
|
cause
|
10
|
10
|
10
|
7
|
10
|
5
|
5
|
10
|
|
purpose
|
0
|
0
|
0
|
0
|
10
|
0
|
8
|
10
|
|
preconditions
|
0
|
7
|
10
|
0
|
8
|
0
|
10
|
10
|
|
ability
|
10
|
5
|
5
|
5
|
2
|
1
|
10
|
1
|
|
accompaniment
|
0
|
5
|
2
|
0
|
0
|
10
|
5
|
7
|
|
content
|
0
|
2
|
5
|
7
|
2
|
10
|
8
|
7
|
|
measure
|
0
|
5
|
2
|
0
|
5
|
2
|
3
|
7
|
|
value
|
3
|
8
|
5
|
10
|
2
|
10
|
8
|
7
|
|
effect
|
10
|
0
|
10
|
5
|
3
|
8
|
10
|
10
|
Putting Tables 1 and 2 together with the a priori
probabilities of the excuses, we can express the suitability of a particular
deception method i for achieving a particular generic excuse j as 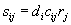 where a is the a
priori suitability of a given deception method, c is the compatibility of that
deception method with a generic excuse, and r is the a priori likelihood of the
excuse condition in a random computer system.
For the parameters in Tables 1 and 2, the best excuse-deception pairs
are shown in Table 3. It is
reasonable to use only those
deception-excuse combinations exceeding a given threshold.
where a is the a
priori suitability of a given deception method, c is the compatibility of that
deception method with a generic excuse, and r is the a priori likelihood of the
excuse condition in a random computer system.
For the parameters in Tables 1 and 2, the best excuse-deception pairs
are shown in Table 3. It is
reasonable to use only those
deception-excuse combinations exceeding a given threshold.
More than one generic excuse can be used, which is
helpful since few excuses defend against all attacks; for instance, "The
network is down" will not excuse the refusal to display a local
directory. However, using multiple
excuses decreases significantly the trust of the attacker as suggested by our
previous example. The excuses
enumerated above are mostly independent, so the simultaneous occurrence of more
than one will have an a priori probability close to the product of their
probabilities and likely be small, which helps the "deception" excuse
which has weak but broad support.
Table 3: The best deception-excuse
combinations as per our parameter estimates.
|
Deception
method
|
Generic
excuse
|
Suitability
|
|
effect
|
net down
|
10
|
|
cause
|
testing
|
9
|
|
cause
|
net down
|
9
|
|
effect
|
bugs
|
8
|
|
value
|
testing
|
7.2
|
|
cause
|
bugs
|
7.2
|
|
time-through
|
testing
|
6.4
|
|
frequency
|
testing
|
6.4
|
|
frequency
|
network down
|
6.4
|
|
value
|
comms. faulty
|
5.4
|
Suspiciousness of the Attacker
We assume an intrusion-detection system [24] can
provide the data to calculate a probability that a user is an attacker. This requires recognizing both misuse
signatures (as in Snort) and anomalies, for both user-session information and
all-users global information (in case a malicious user logs in under several
names). Misuse signatures generate high
(but not certain) probabilities of attack, and anomalies such as high system
load give conditional probabilities of attack that can be estimated from test
data. [22] implemented the architecture
we propose to use in which both network-based and host-based open-source
intrusion-detection systems wrote into log files read and used by a deception engine.
COUNTERPLANNING
With our estimate of how effective a set of
deceptions can be, we can construct "counterplans" [7] to foil
attackers. This can be done in advance
of any attack (if we can anticipate certain common attacks) or
dynamically. Good counterplanning tries
to minimize damage to our computer systems.
[25] proposed a theory of piecemeal changes to thwart a detailed attack
plan, but such ad hoc events are unlikely to be as convincing as the integrated
deception provided by generic excuses.
The Penalty for Deceiving Non-Attackers
Our counterplans must specify what generic excuses
we will use and when. We should not
apply an excuse until we are rather sure we are under attack (except for
honeypots, which serve no legitimate purpose and can be deceptive all the
time). On the other hand, the later we
apply the excuse, the more likely an attacker will still achieve their goals,
since the closer people are to a goal, the harder they try to achieve it, and
the more likely they will find some way to achieve it that we have not
anticipated. So some planning is necessary.
Let us assume a ratio r between the value of a
legitimate user achieving their goals on this computer system to the value to
the attacker of achieving their own goals; we expect this to be a small
fraction. Assume 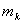 is the probability that the sequence of the first k actions
by the user is malicious, obtained from the abovementioned intrusion-detection
system. Assume C is the cost to us of
the attacker achieving their goals, and
is the probability that the sequence of the first k actions
by the user is malicious, obtained from the abovementioned intrusion-detection
system. Assume C is the cost to us of
the attacker achieving their goals, and 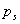 the probability that
they will achieve their goals. Then the
expected cost to us is
the probability that
they will achieve their goals. Then the
expected cost to us is
 . This must be
positive to justify trying to decrease the probability the attacker will
achieve their goals, or that
. This must be
positive to justify trying to decrease the probability the attacker will
achieve their goals, or that 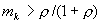 , so this gives an absolute criterion for deception early in
an attack.
, so this gives an absolute criterion for deception early in
an attack.
These formulas can be refined further. Any intrusion-detection system we use to
measure attacker suspiciousness will have "false positives" when a
legitimate user accidentally creates a known attack signature or anomaly. Honest people who have been tricked tend to
react strongly, more so than to setbacks occurring without deceit. So false positives could be ranked as extra
costly in the formula.
A Metric for Counterplanning
As for the planning metric we wish to maximize, for
most attacks this can be the probability that the attacker gives up and goes
away (a "survival rate").
[25] proposed maximizing the amount of time wasted by the attacker, but
this requires considerable knowledge of the attack plan, and could be
dangerous: The more time an attacker spends on our system, the more likely they
will recognize deceptions and figure countermoves (and perhaps tell other
hackers). So we assume we want to
maximize the probability that an attacker gives up, a monotonic function of the
probability of all the non-deception hypotheses. All the generic excuses mentioned encourage an attacker to give
up since they describe serious obstacles preventing their goals from being
achieved. In addition, effects can be
intensified by additional deceptions from Table 1 like extra delays in system
responses. (Giving up on one system may
encourage the attacker to attack another system of ours, but we should install
similar deceptive methods on all our systems.)
Attackers (and legitimate users) can differ
individually in their responses to adversity and deception (in patience, aggressiveness,
etc.) [20]. It is helpful to identify
through experiments those useful clusters of people having similar parameters
to better adapt deceptions to personality.
"Personality tests" like the Myers-Briggs identify such
standardized indicators; we expect that attackers will generally score high on
the "thinking" (vs. "feeling") dimension and "sensing"
(vs. "intuition") dimension, but will vary on the extraversion/introversion
and judging/perceiving dimensions. This
can be exploited to predict their relative likelihood of giving up if we know
something about them, say from observing how they respond to minor setbacks
during their attack. But we believe
individual influences will be minor with the unsubtle generic excuses we have
proposed.
So given this planning metric and some hypotheses
about the attackers, we should use deception as soon as the cost formula says
it is advantageous to do so, and then use it consistently from then on. As to which generic excuses to use, this
depends on the kinds of attack expected.
We can get statistics and simulate the expected effectiveness of our
deceptions on the attack plans as [25] did.
This optimization problem can be addressed with many classic techniques
in operations research and artificial intelligence such as A* search or genetic
algorithms. Several ideas can simplify
the problem. First, absolute optimality
is not critical; we can use heuristics to "satisfice" and get a near-optimal
solution. Second, attackers have a
limited set of goals they wish to achieve (the three most important are
substituting their own copy of an operating system at a site, systematically
searching for secrets, and swamping a resource with transactions so as to
render it useless) and a limited set of methods they use to achieve those
goals. So it is reasonable to enumerate
those plans and figure ways to interfere with each in advance rather than
making decisions during an attack.
Third, we can learn from experience: We can see how volunteers or even
attackers respond to methods we try, and use this to improve our modeling.
The attacker with a single goal like root compromise
can be contrasted with the spy-like attacker that wants to reconnoiter our
system and search for secrets, like those for whom our demonstration honeypot
was designed. Then the time-wasting
metric is appropriate. With information
scattered randomly about, the rate at which the attacker acquires information
will be roughly proportional to the amount of information content they have not
yet examined, or dI/dt = K(1-I) where I is the fraction of the information
content of the computer system that the attacker knows about, t is time, and K
is a constant. Solving this equation we
get 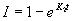 . So we expect that a
spy-like attacker will leave when the slope of this curve,
. So we expect that a
spy-like attacker will leave when the slope of this curve,  decreases to the rate at which the spy values their
expenditure of time. We can lengthen
their stay by increasing the time to obtain information or increasing the
apparent amount of information on the system.
For instance for seven students assigned to explore our honeypot site,
they visited 9, 11, 16, 25, 55, 67, and 95 pages respectively. Assuming they value their time equally, the
differences must be due to the constant representing the amount of value they
obtain from the site. We can solve for
the ratios of the constants for each pair of students. For instance, between the most patient and
least patient students, the ratio is approximately 5.9.
decreases to the rate at which the spy values their
expenditure of time. We can lengthen
their stay by increasing the time to obtain information or increasing the
apparent amount of information on the system.
For instance for seven students assigned to explore our honeypot site,
they visited 9, 11, 16, 25, 55, 67, and 95 pages respectively. Assuming they value their time equally, the
differences must be due to the constant representing the amount of value they
obtain from the site. We can solve for
the ratios of the constants for each pair of students. For instance, between the most patient and
least patient students, the ratio is approximately 5.9.
Example: Deceptions against Rootkit Installation
Once a generic excuse has been chosen, we must
decide when to use it. For example,
consider a rootkit-installation attack on a computer system. An attacker can use many methods (e.g. buffer overflows) to obtain
administrator privileges. But the basic
plan remains the same: (1) Find a vulnerability, (2) escalate privileges, (3)
copy their own software onto the target system, and (4) install it. This entails subtasks like downloads by a
file-transfer utility, decompression of the downloads, copy of the consequent
files to specific locations in the operating system, and testing of the
resultant installation. We can itemize
suitability of the steps of this plan for each category of generic excuses in
Table 4. Again, 0 means unsuitable and
10 means totally suitable. These come
from common sense: For instance, you cannot blame the network for local events,
and you cannot blame communications for compiled operations.
Table 4: Compatibility of system commands with the generic
excuses.
|
Generic excuse /
Attacker action
|
Network
down
|
Testing
|
Bugs
|
Comm.
faulty
|
Policy
change
|
Hacked
|
Joker
|
Deception
|
|
1. scan ports
|
10
|
5
|
5
|
10
|
10
|
5
|
8
|
10
|
|
2. connect at port
|
10
|
5
|
7
|
5
|
7
|
5
|
6
|
7
|
|
3. buffer overflow
|
0
|
10
|
10
|
10
|
7
|
5
|
2
|
10
|
|
4. file transfer from
another site
|
10
|
5
|
5
|
5
|
10
|
7
|
8
|
7
|
|
5. decompress file
|
0
|
7
|
5
|
0
|
5
|
5
|
5
|
5
|
|
6. move file
|
0
|
7
|
5
|
2
|
8
|
5
|
5
|
7
|
|
7. test operating
system
|
2
|
10
|
10
|
2
|
7
|
10
|
8
|
10
|
In deciding whether to use a deception-excuse pair,
these suitabilities provide an additional multiplicative factor. For instance, the excuse of "bugs"
on the computer system should be used for the third and seventh actions where
it is strongly appropriate. It may also
be appropriate at the fourth, fifth, and sixth actions, or at least one of them
as a way to reinforce the message for the third action; partly suitable actions
entail optional excuses. As for at the
second action, connecting at a port after a port scan is not a certain
indicator of an attack (a legitimate user may just be logging in then), but a
reasonable probability of maliciousness might be 0.2, and a reasonable value of
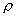 for many systems is
0.1. So the inequality for justifying
deception holds since 0.2+(0.1*0.2)-0.1 > 0, although its worth is decreased
by the 0.7 suitability.
for many systems is
0.1. So the inequality for justifying
deception holds since 0.2+(0.1*0.2)-0.1 > 0, although its worth is decreased
by the 0.7 suitability.
Attack analysis
is better the more you know about attack plans; CMU's CERT publishes much
useful information. We can formulate
those plans using a variety of planning models [10, 19]; [28] provides useful
components for general such modeling.
Modeling also benefits if we estimate work necessary for an attacker to
counter each of our deceptive ploys ("plan repair") [25]. For instance, if we lie and say a downloaded
file is no longer present, the attacker will need to download it again,
requiring a certain amount of wasted time.
Deceptive ploys requiring significant work to repair will significantly
increase the probability that the attacker gives up because they increase the
attacker's frustration.
Consistency
As discussed earlier, inconsistency decreases the
probability of a generic excuse while leaving the probability of deception
untouched. That means that once an
excuse is given, it should be given for all similar situations. So for instance if we complain of
"network problems" for a download, we should complain or give other
similar evidence of network problems at every subsequent occasion that the same
user requires the network. We should
also decrease the threshold for this deception for other users logged in at the
same time since they may be persona of the same attacker.
Table 5 shows an example of consistency with the
"you broke it" excuse. FTP is
a file-transfer utility. IS is the
intrinsic suspiciousness of the action, and CS is the cumulative suspiciousness
taking context also into account. Because
user U2 tried to get something suspicious from site S earlier, the overly-soon
second login for user U1 (likely to then be U2) also trying to get the same
file is consistently denied file transfers, whereas earlier user U1 was not impeded.
Table 5: Example of reasoning
for deception.
|
Time
|
User: Action
|
IS
|
CS
|
Response
|
|
800
|
U1:
login
|
0.0
|
0.0
|
normal
|
|
805
|
U1:
edit paper1
|
0.0
|
0.0
|
normal
|
|
808
|
?:
scan ports
|
0.4
|
0.4
|
normal
|
|
812
|
U2:
connect at port 6520
|
0.2
|
0.2
|
normal
|
|
813
|
U2:
ftp encrypted file EF from site S
|
0.3
|
0.5
|
say
file too big and network down
|
|
814
|
U1:
ftp paper2 from site T
|
0.1
|
0.1
|
normal
|
|
815
|
U1:
logout
|
0.0
|
0.0
|
normal
|
|
821
|
U1:
login
|
0.1
|
0.1
|
normal
|
|
822
|
U1:
ftp EF from S
|
0.3
|
0.7
|
say
network down
|
|
823
|
U1:
ftp encrypted file ER from U
|
0.3
|
0.8
|
say
network down
|
Similarly, we must also be consistent in the
deception methods we choose. If we lie
that the network is down at some point, we should not later claim security
policy is being violated by network transmissions, even though that is an
equally valid excuse for disallowing network operations. There are, however, exceptions to the
principle of consistency. If the
file-transfer utility breaks only when the attacker tries to transfer suspicious
files, the attacker will get suspicious.
It is better to use the "you broke it" strategy just once and
prevent all file transfers after one suspicious one is attempted. In general, it is best to avoid consistent
unusual events.
It is true that an attacker not fazed by our first
deceptive ploy is less likely to respond to a second or subsequent ploy. Nonetheless, consistency is still important
because attacker behavior in the face of surprises is often an attempt to
confirm the surprise by a kind of "hypothesis
testing." At that point, attacker
reasoning no longer assumes that evidence probabilities are independent since a
common explanation is being proffered.
For instance, the joint probability that both word-processing software
and file copying don't work in a computer system is considerably more than the
product of the individual probabilities because several common hypotheses
explain both, including "file system not working" and "testing
is being done."
How do we obtain good probabilities of what
attackers will do with and without deception?
We need to do human-factors experiments, either with volunteers or with
real attackers in honeypots. We can
foist deceptions on them or not and record statistics on how they respond. We may also be able to infer the worth that
attackers give to their own work time and to achieving their goals, something
that will vary considerably between attackers and between situations. Each time an attacker continues attacking
our system, they are giving us an inequality between the expected value of a
successful attack on our system and other targets; each time the attacker gives
up an attack, we have an inequality in the other direction. We can use methods of linear programming to
find points on the boundary of the region of parameter space that satisfies
these inequalities, and find its centroid.
CONCLUSIONS
Deception is a key part of human nature. Cyber-attackers have used deceptions for a
long time to achieve their goals. It is
only fair that defenders respond in kind.
So we need a good theory of how deception operates both offensively and
defensively. Simple defensive deceptions
can be easy to implement, easier than configuring and implementing access
controls on every resource of an information system. We need to start deception planning for important information
systems on a routine basis. The
techniques are not difficult, but do require some care to choose among the many
options available.
ACKNOWLEDGMENTS
This work is part of the Homeland Security Leadership
Development Program supported by the U.S. Department of Justice Office of
Justice Programs and Office for Domestic Preparedness.
REFERENCES
[1]
Applegate, C., Elsaesser, C., & Sanborn, J., An architecture
for adversarial planning, IEEE
Transactions on Systems, Man, and Cybernetics, 20 (1), January/February
1990, pp. 186-194.
[2]
Austin, J. L., How To Do
Things With Words. (2nd ed., ed. by J.O. Urmson & M. Sbis). Oxford:
Oxford University Press, 1975.
[3]
Barber, R. S., and Kim. J., Belief revision process based on
trust: agents evaluating reputation of information sources. In Falcone, R., Singh, M., and Tan, Y.-H.
(eds.), Trust in Cyber-Societies,
LNAI 2246 (Berlin: Springer-Verlag, 2001), 73-82.
[4]
Bell, J. B., & Whaley, B., Cheating. New York:
Transaction Publishing, 1991.
[5]
Bishop-Clark, C., & Wheeler, D., The Myers-Briggs
personality type and its relationship to computer programming. Journal
of Research on Technology in Education, Vol. 26, No. 3, pp. 358-370, Spring
1994.
[6]
Bok, S., Lying: Moral
Choice in Public and Private Life.
New York: Pantheon, 1978.
[7]
Carbonell, J., Counterplanning: A strategy-based model of
adversary planning in real-world situations, Artificial Intelligence, Vol. 16, 1981, pp. 295-329.
[8]
Carley, K., Inhibiting adaptation, Proc. Command and Control Research and Technology Symposium, Monterey
CA, USA, June 2002.
[9]
Carofiglio, V., de Rosis, F., & Castelfranchi, C., Ascribing
and weighting beliefs in deceptive information exchanges. Proc. User Modeling, 2001, 222-224.
[10] Cohen, F.,
Simulating cyber attacks, defenses, and consequences. http://all.net/journal/ntb/simulate/simulate .html, May 1999.
[11] Copeck, T.,
Delisle, S., & Szparkowicz, S., Parsing and case interpretation in TANKA.
Conference on Computational Linguistics, Nantes, France, pp. 1008-1023, 1992.
[12] De Rosis,
F., Castelfranchi, C., Carofiglio, V., & Grassano,
R., Can computers deliberately deceive? A simulation tool and its application
to Turing's imitation game. Computational Intelligence, to appear
2004.
[13]
Dunnigan, J. F., & Nofi, A. A., Victory and Deceit, second edition: Deception and Trickery in War. San Jose, CA: Writers Club Press, 2001.
[14]
Fillmore, C., The case for case. In Universals in Linguistic
Theory, ed. Bach & Harns, New York: Holt, Rinehart, & Winston,
1968.
[15]
Ford, C. V., Lies! Lies!!
Lies!!! The Psychology of Deceit.
Washington, DC: American Psychiatric Press, 1996.
[16]
Fowler, C. A., & Nesbit, R. F., Tactical deception in
air-land warfare. Journal of Electronic Defense, Vol. 18, No. 6 (June 1995), pp.
37-44 & 76-79.
[17]
Heuer, R. J., Cognitive factors in deception and counterdeception. In Strategic
Military Deception, ed. Daniel, D. C., & Herbig, K. L., New York:
Pergamon, 1982, pp. 31-69.
[18]
The Honeynet Project, Know
Your Enemy. Boston: Addison-Wesley, 2002.
[19]
Lowry, J., An initial foray into understanding adversary
planning and courses of action. Proc.
DARPA Information Survivability Conference & Exposition II, Anaheim, CA,
June 2001, vol. 1, pp. 123-133.
[20]
Lydon, J., & Zanna, M., Commitment in the face of
adversity: A value-affirmation approach, Journal
of Personality & Social Psychology, Vol. 58, No. 6, June 1990, pp.
1040-1047.
[21]
McClure, S., Scambray, J., & Kurtz, G., Hacking Exposed: Network Security Secrets
and Solutions, third edition. New
York: McGraw-Hill Osborne Media, 2001.
[22]Monteiro, V., How intrusion detection can improve software
decoy applications. M.S. thesis, U.S.
Naval Postgraduate School, March 2003,
www.cs.nps.navy.mil/people/faculty/rowe/oldstudents/monteiro_thesis.htm.
[23]
Nelms, H., Magic and
showmanship: A handbook for conjurers.
Mineola, NY: Dover, 1969.
[24]
Proctor, P. E., Practical
intrusion detection handbook. Upper
Saddle River, NJ: Prentice-Hall PTR, 2001.
[25]
Rowe, N. C., Counterplanning deceptions to foil cyber-attack
plans. Proc. 2003 IEEE Workshop on
Information Assurance, West Point, NY, June 2003, 203-211.
[26]
Smith, H. A., The
compleat practical joker. Garden
City, NY: Doubleday, 1953.
[27]
Sztompka, P., Trust. London: Cambridge University Press, 1999.
[28]
Templeton, S., & Levitt, K., A requires/provides model for
computer attacks. Proc. of the New
Security Paradigms Workshop, Cork, Ireland, September 2000.
[29]
Tognazzini, B., Principles, techniques, and ethics of stage
magic and their application to human interface design. Proc. Conference on Human Factors and
Computing Systems (INTERCHI) 1993, Amsterdam, April 1993, pp. 355-362.
[30]
Ward, D., & Hexmoor, H., Toward deception in agents. Proc. 2nd Intl. Joint Conf. on
Autonomous Agents and Multi-Agent Systems, Melbourne, Australia, pp. 1154-1155,
July 2003.
[31]
Whaley, B., Towards a general theory of deception. Journal
of Strategic Studies, Vol. 5, No. 1, pp. 179-193, March 1982.
[32] Witten,
I., & Frank, E, Data mining:
Practical machine learning with Java implementations. San Francisco, CA: Morgan Kaufmann, 2000.Top of Form