Absolute bounds on the mean and standard deviation of transformed data for constant-sign-derivative transformations
Neil C. Rowe
Department of Computer Science, Code CS/Rp, Naval Postgraduate School, Monterey , CA 93943, ncrowe at nps.navy.mil
Abstract
Absolute bounds (or inequalities) on statistical quantities are often a desirable feature of statistical packages since, as contrasted with estimates of those same quantities, they can avoid distributional assumptions and can often be calculated very fast. We investigate bounds on the mean and standard deviation of transformed data values, given only a few statistics (e.g. mean, standard deviation, minimum, maximum, median) on the original data values. Our work applies to transformation functions with constant-sign derivatives (e.g. logarithm, antilog, square root, and reciprocal). We can often get surprisingly tight bounds with simple closed-form expressions, so that confidence intervals are unnecessary. Most of the results of this paper seem to be new, though they are straightforward to derive by geometrical arguments and analytical optimization methods.
The work reported herein was supported in part by the Foundation Research Program of the Naval Postgraduate School with funds provided by the Chief of Naval Research, and in part by the Knowledge Base Management Systems Project at Stanford University under contract #N00039-82-G-0250 from the Defense Advanced Research Projects Agency of the U.S. Department of Defense.
This paper appeared in SIAM Journal of Scientific and Statistical Computing, 9, 6 (November 1988), pp. 1098-1113. The equations were redone in 2008 and some errors were fixed. Keywords: inequalities, transformations, statistical bounds, mean, standard deviation, order statistics, exploratory data analysis, optimization, nonparametric estimation, antisampling
1. Introduction
Standard transformations of numeric data values such as logarithm, antilog, square root, square, cube, and reciprocal are frequently appropriate as a prelude to statistical analysis of finite data sets (Hoyle73). Sometimes, however, the data are already aggregated into counts and means, and the original data values lost. This happens when the original data is too large to handle and/or contains sensitive information, as the U.S. Census, which publishes much of its data as aggregates. We may also deliberately create "database abstracts" of aggregate statistics to enable quick statistical estimates by "antisampling" methods (Rowe85). Statistics on the transformed values cannot be calculated uniquely when the original data is so preaggregated. (Even if the data is transformed before being aggregated, there are still reasons to want statistics on the untransformed data; to use the example of (Hoyle73), it is useful to study rainfall in the cube root of inches, but studies of inches itself can be useful in other ways.). But if we are doing exploratory data analysis (Tukey77, Hoaglinetal83), an estimate or bound on a statistic of the transformed data may suffice.
Absolute bounds on statistics of transformed data have several advantages over estimates of those same statistics. (1) Absolute bounds can be narrow for smooth transformations; and tight enough bounds can be equivalent to a good estimate. (2) Unlike estimates (NeymanScott60), bounds need not require distributional assumptions nor analysis of estimator bias. (3) An estimate of a statistic can be logically inconsistent when bounds are tight, i.e. it may be outside the bounds. (4) As (Hoyle73) discusses, confidence intervals for the mean and standard deviation of transformed data are difficult to obtain and methods have exceptions. (5) Users of statistical packages can be mathematically naive and have difficulty understanding confidence intervals, but can understand bounds. (6) Some important algorithms need only bounds, as the branch-and-bound and A* search algorithms. (7) Graphical display can only show data at a finite degree of resolution, and bounds can fall within that resolution. (8) The derivation of simple bounds formulae is straightforward. (9) Simple bounds formulae are quickly computable, making them well suited for computer implementation. (10) We have identified other advantages of bounds in previous work (Rowe83, Rowe85, Rowe88).
An alternative to obtaining absolute bounds on means and standard deviations of transformed data is to study the order statistics (besides the minimum and maximum), which map directly to counterparts under constant-sign transformations. However, order statistics may be unavailable if preaggregation of the data into counts or sums has been done, as with the Census or our "antisampling" techniques. Also, many statistically naive users often do not feel as comfortable with order statistics as with the means and standard deviations, so it may be desirable to provide the bounds discussed here anyway when order statistics are available.
An alternative to the bounds formulae in this paper is obtaining bounds through direct optimization by computer on a set of variables representing the values or probability weights of an unknown discrete distribution. However, direct optimization can be indefinitely slow, whereas our closed-form formulae have a fast fixed computation time. Direct-optimization efficiency is highly sensitive to the choice of optimization method, starting point, and step size, and it may be difficult to make converge, as the function optimized is not usually convex. And when such a process does not run long enough to reach the true optimum, it will give a lower bound on an upper bound, or an upper bound on a lower bound, unlike the formulae of this paper which are guaranteed to be true bounds. These are very serious disadvantages.
The main argument of this paper is that exploitation of the minimum and maximum of the data values for a population may give surprisingly tight bounds on transformed values. The minimum and maximum statistics are easy for computers to calculate as opposed to other order statistics. Furthermore, they can usually be bounded when not known exactly, as by intersecting ranges when a population is the intersection of sets with known ranges.
This paper is intended to serve as a catalog of useful bounds for computer implementation. The most important of our formulae are summarized in the next section; most readers need not read beyond this summary.
2. Summary of major results
Let t(x) be the transformation function. Let μ be the mean of the original (untransformed) data values, σ the standard deviation, m the minimum, and M the maximum. Assume the first three derivatives of t(x) are constant-sign in the interval between m and M. Also to simplify analysis, assume that the second derivative is positive; we can always analyze the negative of a negative-derivative transformation function, and just take the negative of any bounds on the mean derived.
Note that all the following bounds are closed-form expressions, each involving less than twenty arithmetic operations or comparisons per untransformed-data statistic, so each can be computed within 50 microseconds per such statistic on all but the smallest computers. Also note that most seem to be new formulae, taking the inequalities of (Encyclopedia) as the state of the art.
Bounds on the mean of the transformed values (section 4.1):
,
Bounds on the mean of the transformed values (section 4.3) (the first is not necessarily the lower bound):
Bounds on the mean of the transformed values (section 4.4), where we denote
order statistics as r pairs of the form ![]() , where fraction
, where fraction ![]() of the items in the
distribution are claimed to lie at or to the left of value
of the items in the
distribution are claimed to lie at or to the left of value ![]() (and
(and ![]() ):
):
(lower bound, t'(x)>0, else upper)
![]() (upper bound, t'(x)>0,
else lower)
(upper bound, t'(x)>0,
else lower)
Bounds on the mean of the transformed values (section 4.5), given that fraction c of the distribution is at or to the left of value o:
(lower bound,
)
(lower bound,
)
(upper bound,
)
(upper bound,
)
where
Bounds on the standard deviation of the transformed values (section 5.2),
where![]() is the
smaller of the two mean bounds of section 4.3 and
is the
smaller of the two mean bounds of section 4.3 and ![]() is the larger:
is the larger:
![]() (lower
bound, t'(x)>0, else upper)
(lower
bound, t'(x)>0, else upper)
(upper bound, t'(x)>0, else lower)
Bounds on the standard deviation of the transformed values (section 5.4):
lower bound)
![]() (upper bound)
(upper bound)
![]() (lower bound)
(lower bound)
![]() (upper bound)
(upper bound)
where ![]() .
.
Bounds on the mean of the transformed values (section 6.1), given that the
data distribution is approximated by p(x) with maximum and minimum errors ![]() and
and ![]() :
:
 and
and

where  , and p(x) is the distribution the
, and p(x) is the distribution the ![]() fit to.
fit to.
3. Preliminaries
We require transformation functions t(x) whose first three derivatives have a constant sign in the interval of study. (This restriction can be relaxed in particular cases, however; usually only a constant-sign t''(x) is necessary. Chapter 3 of (Hardyetal52) discusses more detailed restrictions for the bounds in the first part of the next section.) The "power transformations" and their inverses (Emerson83) (e.g. log, antilog, square root, square, cube, and reciprocal) satisfy this restriction for positive data values. To simplify matters, we further assume that t''(x)>0; negative-second-derivative curves can be handled by considering their negative.
We assume that the mean (μ), minimum (m), and maximum (M) of the original (untransformed) data values are known (or a lower bound on the minimum and an upper bound on the maximum). Optionally, the standard deviation (σ) or order statistics may also be known. We will define the standard deviation with a denominator of n instead of n-1, and use the symbols μ and σ, to emphasize that we consider finite data populations which are not necessarily samples of anything.
We will ignore linear transformations before or after other transformations,
since these can be handled trivially. For instance, t(x) = ln(ax+b) can be
analyzed by defining y=ax+b and analyzing g(y)=ln(y), where ![]() and
and ![]() .
.
We will use two techniques to obtain bounds: finding curves that bound the transformation function in the interval of interest, and analytic optimization using formulae for the statistics. While the latter is more elegant and is preferable, it becomes unworkably complex for certain bounds situations, most notably for bounds on the standard deviation.
4. Bounds on the mean of the transformed values
4.1. Linear bounds given the untransformed minimum, maximum, and mean
One way to obtain bounds is to find functions that are either entirely above
or entirely below the curve of the transformation function t(x) between the
minimum (m) and maximum (M), and compute statistics on values transformed by
these bounding functions instead. For straight lines, one bounding function can
be a tangent to the transformation function at the mean, the other a secant of
the curve through it at the minimum and the maximum. (It is straightforward by
calculus to show that this gives the optimal bounds on both sides.) Note if ![]() for all x in a
range, t(x) some transformation functions satisfying our restrictions, and E
denoting expected value, then
for all x in a
range, t(x) some transformation functions satisfying our restrictions, and E
denoting expected value, then ![]() , or
, or ![]() . E(t(x)) is the quantity we are
interested in bounding. The tangent to t(x) at
. E(t(x)) is the quantity we are
interested in bounding. The tangent to t(x) at ![]() gives a well-known bound
(generalized in (Hardyetal52), p. 70), a lower bound under our assumption that
the second derivative is positive:
gives a well-known bound
(generalized in (Hardyetal52), p. 70), a lower bound under our assumption that
the second derivative is positive: ![]() . The secant through the maximum and
minimum gives the upper bound
. The secant through the maximum and
minimum gives the upper bound ![]() , where
, where ![]() .
.
4.2. Comments on the linear mean bounds
The two bounds can be related by rewriting as ![]() and
and ![]() , where
, where ![]() so they
represent interchanging of a weighting and functional application.
so they
represent interchanging of a weighting and functional application.
For a particular ![]() ,
the difference between the bounds is
,
the difference between the bounds is ![]() where
where ![]() which is a maximum if
which is a maximum if ![]() or when the
tangent and secant bounding lines are parallel. For specific t(x) we can
tabulate the maximum error from this formula, as a function of m and M:
or when the
tangent and secant bounding lines are parallel. For specific t(x) we can
tabulate the maximum error from this formula, as a function of m and M:
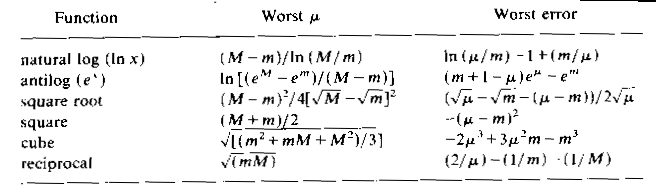
A simple application of the linear bounds on the mean of
transformed values is to bounding the variance of a population given only m, M,
and ![]() . That
is a transformation
. That
is a transformation ![]() , so bounds are 0 and
, so bounds are 0 and ![]() .
.
4.3. Bounds given the untransformed minimum, maximum, mean, and standard deviation
Bounding the mean of some transformed values is mathematically equivalent to finding a probability distribution consistent with the given information about the untransformed values such that the transform mean is an extremum. General solutions to such problems can be obtained from the calculus of variations, but for our particular problem we can show that a discrete probability distribution will suffice, and in particular a two-point distribution, so analysis is much simpler.
Suppose we assume an n-point distribution will suffice, for some arbitrary
n. Then we seek to extremize ![]() such that
such that ![]() .
.
Solving this using the method of Lagrange multipliers, it follows that the secant between any two solution points on the curve for t'(x) must be a constant. But since we assume the third derivative of t(x) is constant sign, this would mean two secants from the same point would have the same slope, which is impossible. Therefore the discrete probability distributions that extremize the mean of the transformed values have at most two points.
It is now straightforward to solve for the locations of the two points and their associated probabilities. There is no unconstrained optimum, but there are two bounds obtained by making either of two inequality constraints on x active, by setting one point to an extreme (no distribution can satisfy the constraints in nontrivial cases if the probability of either point is a probability extremum of 0 or 1):
There is a nice geometric explanation of these bounds (see Figure 1). The
first is a weighted average of the values of t(x) determined by a secant
through the curve between the minimum and a "balancing" point to the
other side of the mean; the other bound is the corresponding weighted average
involving the maximum point. The bounds are the heights of the secants at x=μ.
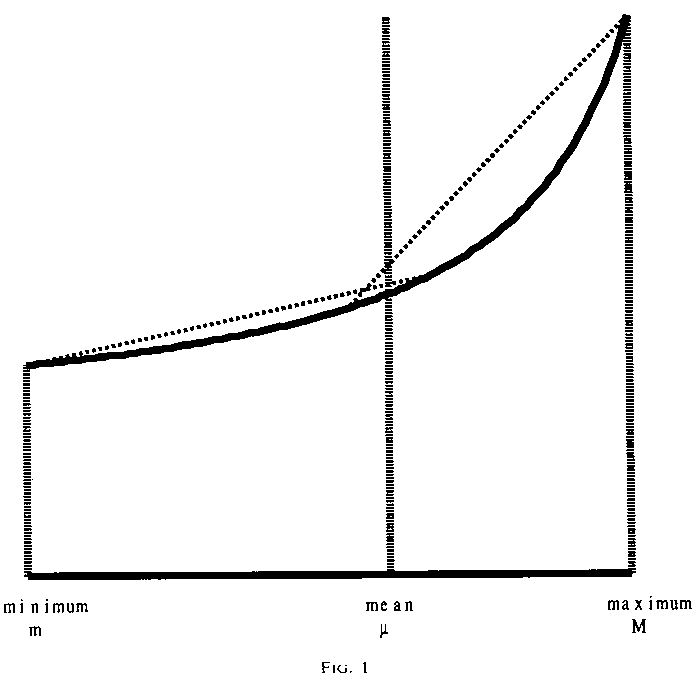
We cannot say in general which of these bounds is the lower and which is the upper: it all depends on whether the two secants intersect to the left or right of μ . But these bounds must be better than the linear bounds of section 4.1, since the tangent to the curve at the mean and the secant across the function between its minimum and the maximum both intersect x=μ outside our new bounds, and those points of intersection are the linear bounds.
4.4. Bounds from order statistics alone
Order statistics on the untransformed values map directly to the same order statistics on the transformed values. But order statistics can also help bound the mean of the transformed values.
Suppose we know a set of r order statistics in the form ![]() where
where ![]() is an x value and
is an x value and ![]() is the fraction
of the values of the data population that are at or to the left of that
is the fraction
of the values of the data population that are at or to the left of that ![]() . Then clearly the
extremes of the mean of the transformed values, given no information about the
mean and standard deviation of the untransformed values, are when the values in
the distributions are pushed right and pushed left as far as they can go,
respectively. So the bounds are
. Then clearly the
extremes of the mean of the transformed values, given no information about the
mean and standard deviation of the untransformed values, are when the values in
the distributions are pushed right and pushed left as far as they can go,
respectively. So the bounds are ![]() where we take
where we take ![]() .
.
4.5. Bounds from the untransformed mean as well as order statistics
Suppose we are given the mean of the untransformed values as well as some order statistics. Then bounding the mean of the transformed values is quite complicated in general. But we do it without too much trouble in the simplest case of a single order-statistic point o and associated fraction c (the portion of the distribution at or to the left of o). Then with similar techniques to those in section 4.3, it is straightforward to show that the distributions that extremize the mean of the transformed values are discrete and contain no more than three values. Furthermore, at most two of those values must be from the three boundary points in this situation (m, o, M), and the other possible point (call it x) must have an associated probability that is an extremum consistent with the order-statistic information. This follows because (1) if there were more than one point in the distribution not either m, o, or M, then t'(x) at those points would be equal; (2) if all three of m, o, and M were in the distribution, then the three secants across the curve between them would have the same slope, (3) if the probability of the unfixed distribution point were not an extremum, t'(x) there would have to be equal to a secant from that point. So there are four cases, any of which can provide bounds for a problem:
Extremizesubject to
or
Extremizesubject to
or
Extremizesubject to
or
Extremizesubject to
.
The first two cases have a unique solution, but the latter two do not have
an inequality-unconstrained optimum since the t'(x) would be equal to the slope
of the secant through the other two points mentioned, which is impossible
because the inequality constraints require x to lie outside the interval between
the other two points. To get a bound in the last two cases, we must choose an
inequality constraint to make active. So we have eight expressions, the first
four from taking probabilities to be extremes, and the last four from taking x
to be an extremum: ![]()
![]()
where.
(Note that following section 4.4 with t(x)=x, ![]() and
and ![]() for the
statistics to be consistent. Thus
for the
statistics to be consistent. Thus ![]() and
and ![]() ; those are necessary additional
conditions on each of the above eight formulae.)
; those are necessary additional
conditions on each of the above eight formulae.)
In turns out that Z3 and Z4 are the global upper bounds and Z7 and Z8 are the global lower bounds in the above. It is straightforward to prove this using three lemmas for a t''(x)>0: (L1) a secant must lie above every point on the curve between the endpoints of the secant; (L2) a secant across a subinterval of the interval of another secant must lie below that secant; and (L3) a secant from x to z, x<z, must lie above the secant from x to y, x<y<z. So Z5 upper-bounds Z7 and Z8 by L2, and Z6 upper-bounds Z7 and Z8 by L2. Z3 upper-bounds Z5 by L1, and Z4 upper-bounds Z6 by L1. Z1 upper-bounds Z7 by L3, and Z2 upper-bounds Z8 by L3. And Z3 and Z4 upper-bound Z1 and Z2 by L3.
Hence the bounds are:
where
As a simple application, let ![]() . Then bounds on the standard deviation
given m, M and μ are:
. Then bounds on the standard deviation
given m, M and μ are:
(lower bound,
(lower bound,
)
(upper bound,
(upper bound,
)
The first two are a form of one of Cantelli's inequalities.
4.6. A demonstration evaluation of the bounds
We compare evaluations of our mean-bounds formulae for example situations in
Tables 1 and 2. The formulae compared are the mMμ bounds (section 4.1),
the mMμσ bounds (section 4.3), the mMoc bounds (section 4.4), and the
mMocμ bounds (section 4.5). Table 1 shows results for t(x)=ln(x), and
Table 2, t(x)=1/x. The figures were calculated by a program written in
C-PROLOG. As could be expected, the standard deviation is very helpful in
narrowing the bounds range, and is only surpassed in utility by the
order-statistic information in certain cases when the order statistics are far
from the mean.


5. Bounds on the standard deviation
Unfortunately, the analytic optimization approach of sections 5 and 6.2 is too complicated for finding bounds on the standard deviation of the transformed values: it often does not work at all, and when it does work, it gives equations that must be solved iteratively. So for fast closed-form bounds expressions, we must use bounds-line arguments as in section 4.1.
5.1. Bounds given the untransformed mean, minimum, and maximum
We need different bounds lines than those for the mean. First, assume we
know the exact mean of the transformed data values--call it ![]() . With t'(x) constant-sign,
. With t'(x) constant-sign, ![]() is unique, so
let
is unique, so
let ![]() .
To get an upper bound on the standard deviation for t'(x)>0, we could use a
"secant" line below t(x) for m<x<η and above t(x) for η<x;
and to get a lower bound, we could use a secant line above t(x) for x<η
, and below for η<x<M (see Figure 2). (Vice versa for t'(x)<0.)
That is, the lines:
.
To get an upper bound on the standard deviation for t'(x)>0, we could use a
"secant" line below t(x) for m<x<η and above t(x) for η<x;
and to get a lower bound, we could use a secant line above t(x) for x<η
, and below for η<x<M (see Figure 2). (Vice versa for t'(x)<0.)
That is, the lines:
This works because if t''(x)>0 in the interval, the
secant across t(x) from m to η must lie entirely to one side of t(x).
Furthermore, its extension to the right of ![]() must lie entirely to the other side
because t(x) is curving away from the line then; similarly for the other
secant.
must lie entirely to the other side
because t(x) is curving away from the line then; similarly for the other
secant.

Now the variance of ![]() is:
is:

and so the standard deviation of the transformed values is bounded by
(lower bound, t'(x)>0; upper bound, t'(x)<0)
(upper bound, t'(x)>0; lower bound, t'(x)<0)
or an adjusted standard deviation of the original values times the slopes of the lines from the mean of the transformed values to the minimum and maximum on the interval.
5.2. Handling an unknown transformed-value mean
This assumes we know η, the mean of the transformed values, exactly. Otherwise, we can prove that the bounds formulae of the last section have no extrema as η varies within the range m to M. For instance, assume t'(x)>0 and consider the lower bound. The derivative with respect to η of the square of it is:
where
The ![]() is positive, and
is positive, and ![]() , so the first term in
the sum in positive. Since t''(x)>0,
, so the first term in
the sum in positive. Since t''(x)>0, ![]() is positive, and the second term is
positive. Therefore the whole formula is positive.
is positive, and the second term is
positive. Therefore the whole formula is positive.
Similar analysis can be applied to the other three cases, except that the
derivative of the bound square is negative when t''(x)<0. Thus the best
bounds on the transformed-value standard deviation occur for the two extremes
of η found by the methods of section 4.3; call the lower extreme ![]() and the upper,
and the upper, ![]() . Thus the bounds when
t'(x)>0 are:
. Thus the bounds when
t'(x)>0 are:
(lower bound, t'(x)>0, else upper)
5.3. Bounds given order statistics as well
Order statistics bound further the standard deviation of the transformed
values, especially order statistics for points far to one side of the range.
The bounds lines of section 4.1 had to cross t(x) only once between m and M,
and this was highly conservative. We might get a better bound if we knew what
fraction c of the distribution lay to the left of some point o, and the drew a
secant of t(x) from the transform mean η to o instead of m. To get bounds
with these new lines, we need a correction term for the points lying more
extreme than o. Assume η is known exactly and ![]() . Then the correction
corresponds to the worst case in which all the c probability is at m, which
means a difference in the variance of
. Then the correction
corresponds to the worst case in which all the c probability is at m, which
means a difference in the variance of ![]()
So general bounds on the standard deviation are
(lower bound)
(upper bound)
where
So using such bounds lines can slopes more alike, but one pays a penalty of a correction term which counters the slope improvement. An obvious question when the order statistic helps; this has a surprising answer. Considering each of the four above formulae separately, the conditions on superiority of bounds with the order statistic to those without are (after cancelling out terms and combining):
(lower bound if t'(x)>0, else upper)
(upper bound if t'(x)>0, else lower)
Note these formulae are independent of o, where the order statistic is within the distribution, except for which side of η that o is on.
5.4. Handling an unknown transformed-value mean with order statistics
If the mean of the transformed values is not known exactly, we cannot give a nice result like section 5.2 unless we make certain additional assumptions. For instance, the derivative of the first bound above (for t'(x)>0 and o<η) is:
where ![]() and
and ![]() .
.
With the assumption that the first two derivatives are
positive, ![]() and
and
![]() are
positive; and the expression in brackets must positive for the bound to be
useful, as the last section shows. So the third of the three big summed terms
must be positive. Since
are
positive; and the expression in brackets must positive for the bound to be
useful, as the last section shows. So the third of the three big summed terms
must be positive. Since ![]() ,
, ![]() is positive. So to ensure that the
entire above derivative of the bound is positive, a sufficient condition is
that
is positive. So to ensure that the
entire above derivative of the bound is positive, a sufficient condition is
that ![]() .
.
By analogous reasoning, similar formulae can be found for the other three
cases. Then the following bounds apply (where ![]() is the lower bound on η ,
is the lower bound on η , ![]() the upper):
the upper):
![]() (upper bound)
(upper bound)
![]() (lower bound)
(lower bound)
![]() (upper bound)
(upper bound)
where ![]() .
.
5.5. A demonstration evaluation of the bounds
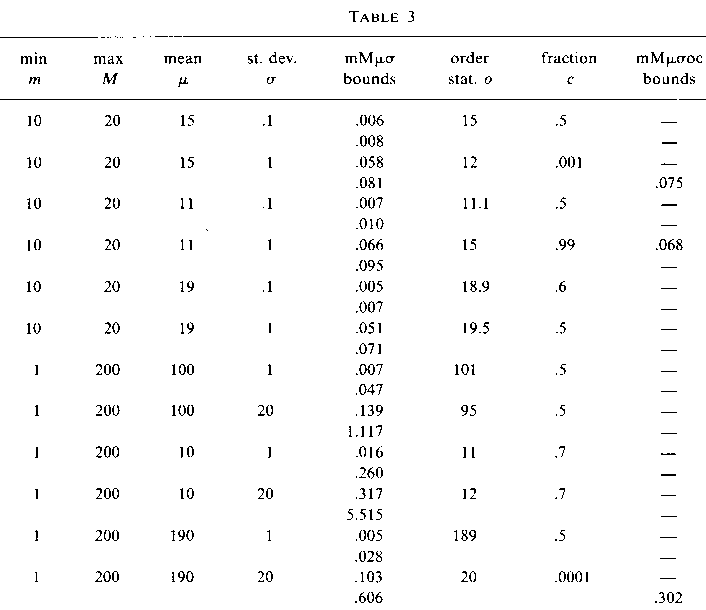
Table 3 shows some demonstration evaluations of our bounds on the standard
deviation, for the function t(x)=ln(x).
6. Bounds using fits to known distributions
A different kind of information which we might have about some data values would be the closeness of their distribution to some well-known one; high closeness implies tight bounds on statistics of the transformed values. For instance, if a certain distribution approximates a normal curve, we could ask that statistics on the error to the curve be calculated, numbers perhaps more interesting and useful than statistics on the data values themselves, as well as requiring less computer storage by being smaller numbers. But this requires anticipation of the form of the distribution, and the ability to control data collection methods, which (as with the U.S. Census data) can be impossible.
6.1. General formulae
A well-known result (e.g. (FreundWalpole80), section 7.3) gives the
distribution of the transform of some probability distribution p(x), under the
transformation function t(x), as ![]() as a function of y, provided t'(x)
is constant-sign.
as a function of y, provided t'(x)
is constant-sign.
To bound means and standard deviations, we can define an "upper
fit" omega sub U and "lower fit" omega sub L on the discrete set
of n values ![]() such
that
such
that ![]() where
where
 , and p(x) is
the distribution the
, and p(x) is
the distribution the ![]() fit to.
fit to.
In other words, the fits are the maximum and minimum
deviations of an ![]() from
its value predicted by the approximating distribution p(x). If t'(x) is
constant-sign, the bounds on the mean of the transformed values occur when the
from
its value predicted by the approximating distribution p(x). If t'(x) is
constant-sign, the bounds on the mean of the transformed values occur when the ![]() are all at
are all at ![]() or all at
or all at ![]() from their
predicted positions, not necessarily respectively, following the same reasoning
as section 4.4. That is:
from their
predicted positions, not necessarily respectively, following the same reasoning
as section 4.4. That is:
and
where , and p(x) is the distribution the ![]() fit to.
fit to.
We can use this same approach bound the variance. Define ![]() as a new
transformation function, and compute the above formulae with h instead of t.
Then compute bounds on the mean, square them, and subtract this interval from
the h interval.
as a new
transformation function, and compute the above formulae with h instead of t.
Then compute bounds on the mean, square them, and subtract this interval from
the h interval.
6.2. Example
Suppose we know the distribution of ![]() fits an even distribution on the
interval 10 to 100, to such an extent that a point is never further than 2
units to the right of where it would be in a perfectly even distribution, and
never more than 3 units to the left. Then the maximum-mean distribution is a
uniform distribution from 12 to 102, and the minimum-mean distribution is a
uniform distribution from 7 to 97. Suppose we want to find the mean of the
logarithms of these data values. If p(x) approximates a uniform distribution on
the interval 10 to 100,
fits an even distribution on the
interval 10 to 100, to such an extent that a point is never further than 2
units to the right of where it would be in a perfectly even distribution, and
never more than 3 units to the left. Then the maximum-mean distribution is a
uniform distribution from 12 to 102, and the minimum-mean distribution is a
uniform distribution from 7 to 97. Suppose we want to find the mean of the
logarithms of these data values. If p(x) approximates a uniform distribution on
the interval 10 to 100, ![]() . For t(x)=ln(x),
. For t(x)=ln(x), ![]() on the interval y=ln(m)
to y=ln(M); an estimate of the mean of q(y) is
on the interval y=ln(m)
to y=ln(M); an estimate of the mean of q(y) is ![]() and an estimate of the second
moment about zero is:
and an estimate of the second
moment about zero is:
which minus the square of the estimate of the mean gives an estimate of the variance.
For our example, the mean of the first distribution is [102 ln(102) - 12 ln(12) - 102 + 12] / (102-12) = (472 - 29.8)/90 - 1 = 5.02 - 1 = 4.02; and the mean of the second distribution is [97 ln(97) - 7 ln(7) - 97 + 7] / (97-7) = (443 - 13.6)/90 - 1 = 4.78 - 1 = 3.78. Hence the mean of the transformed values is between 3.78 and 4.02, corresponding to antilogs of 44 and 56. Note the mean of the original values must lie between (102+12)/2 = 57 and (97+7)/2 = 52.
As for a bound on the standard deviation, we get for the uniform
distribution 12 to 102: ![]()
and for the uniform distribution 7 to 97:
Since bounds on the mean of the transformed values are 3.78 and 4.02, bounds on the square of the mean are 14.3 and 16.2. Hence bounds on the variance are 15.61-14.3=1.3 and max(14.58-16.2,0) = 0.
7. Improving bounds accuracy with outliers and statistics on subsets
We can tighten bounds if we know a few extreme values on the range (outliers), since then we can remove these points from the analysis of the rest of the points. This improves bounds because we have used m and M extensively in our formulae. The transformed values for the outliers can then be weighted in to the total mean or total variance in a final step.
More generally, we may be able to improve bounds anytime we know statistics on disjoint partitions of a set of interest. We can then take weighted sums of bounds on each subset to get the cumulative bounds. Such bounds are usually (but not always) better than the corresponding directly-computed bounds on the full set.
We can prove that the linear bounds on the mean (section 4.1) are always
better. Consider the case of two disjoint subsets, and more complex
subdivisions can be covered by extension. For the lower (tangent) bound, if the
two lower bounds are ![]() and
and ![]() , then the weighted average of the bounds
, then the weighted average of the bounds
![]() is the
intersection of the secant of t(x) between
is the
intersection of the secant of t(x) between ![]() and
and ![]() with the line
with the line ![]() , which must lie above the
lower bound
, which must lie above the
lower bound ![]() for
the union of the two disjoint sets because t''(x)>0. For the upper (secant)
bound, if the ranges of the subsets are the same as the full set, then the two
subset bounds must lie along the same line, and their weighted average must lie
along the line too; hence the bound on the full set is exactly the weighted
average of the two bounds. If one or both of the subsets has a narrower range
than the full set, this can only improve (decrease) the upper bound since a
secant across a subrange must lie below a secant across the range.
for
the union of the two disjoint sets because t''(x)>0. For the upper (secant)
bound, if the ranges of the subsets are the same as the full set, then the two
subset bounds must lie along the same line, and their weighted average must lie
along the line too; hence the bound on the full set is exactly the weighted
average of the two bounds. If one or both of the subsets has a narrower range
than the full set, this can only improve (decrease) the upper bound since a
secant across a subrange must lie below a secant across the range.
8. Extensions
The data population size only significantly affects bounds when it is particularly small, so that the known maximum M and minimum m (and order statistics too, if known) are a nonnegligible fraction of the data of the population. Then we can use the methods of the last section to improve bounds a little.
An application of all these bounds is to bounding statistics on one attribute of some data items from statistics on another, when the attributes are known to have a nonlinear correlation approximable by a function with constant-sign derivatives as we have been using. We can then bound statistics on one attribute from statistics on the other.
9. Conclusion
We have developed some quickly evaluable closed-form expressions for bounds on the mean and standard deviation of a finite set of transformed numerical data values, where the transformation function has derivatives of constant sign in the interval of interest. For this we use only simple univariate summary statistics (particularly the minimum and maximum) on the original set of data values. Our bounds provide a useful alternative to the often difficult-to-obtain confidence intervals, since bounds require no distributional assumptions. Our bounds are likely to be helpful for exploratory data analysis as an aid to getting a feel for the data, preliminary to detailed hypothesis testing.
10. References
(Hoyle73, author "M. H. Hoyle", title "Transformations -- An Introduction and a Bibliography", journal "International Statistical Review", volume "41", number "2", year "1973", pages "203-223", key "Hoyle")
(Rowe85, author "Neil C. Rowe", title "Antisampling for Estimation: An Overview", journal "IEEE Transactions on Software Engineering", year "1985", pages "1081-1091", volume "SE-11", number "10", month "October", key "Rowe85")
(Tukey77, title "Exploratory Data Analysis", author "John W. Tukey", publisher "Addison-Wesley", address "Reading, Mass.", year "1977", key "Tukey")
(Hoaglinetal83, author "David C. Hoaglin, Frederick Mosteller, and John W. Tukey, editors", title "Understanding Robust and Exploratory Data Analysis", publisher "Wiley", address "New York", year "1983", key "Hoaglin et al")
(NeymanScott60, author "Jerzy Neyman and Elizabeth L. Scott", title "Correction for Bias Introduced by a Transformation of Variables", journal "Annals of Mathematical Statistics", volume "31", pages "643-655", year "1960", key "Neyman and Scott")
(Rowe83, author "Neil C. Rowe", title "Rule-based Statistical Calculations on a Database Abstract", institution "Stanford University", address "Stanford, CA", month "June", year "1983", number "STAN-CS-63-975", key "Rowe")
(Rowe88, author "Neil C. Rowe", title "Absolute Bounds on Set Intersection and Union Sizes from Distribution Information", journal "IEEE Transactions on Software Engineering", year "1988", key "Rowe88", volume "SE-14", issue "7", pages "1033-1048")
(Encyclopedia, author "--", title "Encylopedia of Statistical Sciences", key "Encylopedia", publisher "Wiley", address "New York", year "1982")
(Hardyetal52, author "G. H. Hardy, J. E. Littlewood, and G. Polya", title "Inequalities", publisher "Cambridge University Press", address "Cambridge, UK", year "1952", key "Hardy et al")
(Emerson83, author "John D. Emerson", title "Mathematical Aspects of Transformation", booktitle "Understanding Robust and Exploratory Data Analysis", editor "D. Hoaglin, F. Mosteller and J. Tukey", publisher "Wiley", address "New York", year "1983", chapter "8,", pages "247-282", key "Emerson")
(FreundWalpole80, author "John E. Freund and Ronald E. Walpole", title "Mathematical Statistics", publisher "Prentice-Hall", address "Englewood Cliffs, NJ", year "1980", key "Freund and Walpole")