Finding suspicious activity on computer systems
Neil C. Rowe and Simson L. Garfinkel
U.S. Naval Postgraduate School, Monterey, California, USA
ncrowe at nps dot edu
Abstract
Neil C. Rowe
U.S. Naval Postgraduate School
Monterey, California, USA
ncrowe@nps.edu
When computer systems are found during law enforcement, peacekeeping, counter-insurgency or similar operations, a key problem for forensic investigators is to identify useful subject-specific information in a sea of routine and uninteresting data. For instance, when a computer is obtained during a search of a criminal organization, investigators are not as much interested in the machines used for surfing the Internet as the machines used for accounting of drug deals and emailing to co-conspirators. We are doing research on tools to enable investigators to more quickly find such relevant information. We focus on the directory metadata of a computer drive, the listing of the stored files and directories and their properties, since examining it requires much less time than examining file contents. We discuss first what ways people try to hide things on drives. We then discuss clues that suggest concealment or atypical usage of a drive, including encryption, oddities in file names, clusters of deletions, atypical average values, and atypical clusters of files. We report on experiments we have conducted with a corpus of drives purchased from a range of countries. Processing extracted the directory metadata, classified each file, and calculated suspiciousness metrics on the drives. Experimental results showed we could identify some suspicious drives within our corpus but with a certain number of false alarms.
This paper appeared in the Proc. 11th European Conf. on Information Warfare and Security, Laval, France, July 2012.
Keywords: digital forensics, law enforcement, drive classification, metadata, suspicion
1 Introduction
An increasingly important aspect of modern warfare is control of criminal and terrorist activities in occupied territories. This includes searches during law-enforcement, peacekeeping, and counterterrorism operations, and these increasingly encounter computers and other digital devices (Pearson, 2010). The data in the secondary storage or "drives" of these devices can provide considerable information about illegal activities. Drives can also provide information of the development and deployment of cyberarms that we are attempting to control (O'Neill, 2010). We are thus developing methods to automatically aid in assessing drives.
Usually investigators search for files on a drive that contain certain keywords called "selectors." These can be names of particular people and organizations such as drug producers or human traffickers. They might occur in electronic mail, Web-page downloads, and documents. However, inspecting all the contents on a drive takes a good deal of time, as many files are of no interest such as software and operating-system bookkeeping files. So a key challenge for digital forensics is to quickly assess a drive's investigatory value.
We propose a first step to examine just the metadata (directory information) of the file system on the drive (Buchholz and Spafford, 2004). Metadata is typically 1000 times smaller in size than the contents of a drive, and it alone provides sufficient descriptions and statistics about files to give a good picture of what users are doing (Agrawal et al, 2007). Often drives captured during raids were captured by surprise and did not allow owners to conceal or destroy much. So we ought to be able to make discoveries with them.
2 Clues that a drive is of interest
Criminals who are aware that their computers and digital devices could be seized by law enforcement may try to conceal information with anti-forensics techniques (Garfinkel, 2007). Anti-forensics is rare since most users have little need to hide anything besides passwords, so any evidence of it is a clue that a drive is worth inspecting further. (Jahankhani and Beqiri, 2010) enumerates nineteen categories of anti-forensic techniques, some of which can be detected in the metadata alone:
- Media wiping, or erasing of the contents of a drive: Detectable in metadata. It is useful to know even if thorough because it makes other related drives more interesting.
- Steganography (hidden messages): Not detectable in metadata since affects only the contents of the files.
- Anonymization of data: Not detectable, similarly.
- Rootkits: Not detectable.
- Tools for analysis of the hardware: Detectable in metadata.
- Homographic naming, using a name similar to a well-known one: Detectable in metadata.
- Signature modification on files: Ineffective when forensics is used since forensics will create its own signatures.
- Encryption: Detectable in metadata from the file extension or from encryption markers.
- Modified metadata: Not detectable.
- Hiding files in the marked-as-unusable ("slack") space of a disk or in other odd places in the file system (Huebner, Bem, and Wee, 2006): Detectable in metadata if we have it for those parts of the drive, but this requires specialized techniques.
- Files constructed to create deliberate hash collisions with known files: Detectable in metadata.
- Hiding data within memory: Not detectable, but irrelevant if drive can be analyzed.
- Planted misleading evidence: Detectable in metadata if it makes the drive atypical among similar drives.
- Non-encryption encoding of files: Detectable in metadata from the file extension.
- Exploiting of forensic-tool vulnerabilities: Possible but depends on the vulnerability.
- Creation of large numbers of dummy files to confuse analysis: Detectable in metadata.
- Internet anonymization techniques: Not detectable.
- Use of anti-forensics hardware: Not detectable.
Applying these ideas, the following clues can be sought in the metadata of a file system to detect possible concealment and anti-forensics:
· Encrypted files and directories
o Extensions indicating encryption
o Encrypted directories
o Encryption programs
· Suspicious file extensions
o Nonstandard ones, especially long ones and integers
o Double extensions, e.g. "setup.exe.txt"
o Rare extensions
· Deceptive paths (the directory sequence to a file)
o Rare characters such as "{" or the higher-numbered HTML-encoded characters.
o Unnecessarily atypical ways of specifying characters, e.g. "A" for the letter "A"
o Misspellings (e.g. "little figher", "vewing", "addresss"), which can be camouflage
o Engineered hash collisions with very different paths and file names
· Malicious software
o Malware executables, as per extension or filename
o Tools known to be associated with malware or anti-forensics
o Source code of malicious software
· Deletions of files
o Many deletions
o Clusters of deletions around the same time, suggesting attempts to destroy evidence
· Many small similar files or files not accessed after being created, suggesting they were created as decoys.
· Atypical counts of certain file types of interest to investigators. This depends on the investigation but could include email, photographs, video, or program source code.
However, there are also legitimate reasons for the appearance of these clues:
- Encryption is needed to hide sensitive or private information, passwords, and keys.
- Pathnames may use unusual characters if they are created by software.
- Double extensions are used by certain kinds of software.
- Rare extensions may represent rare but legitimate use.
- Malicious software may infect a system without the user being aware of it.
- Some users are atypical in their software use.
- Users delete files in clusters whenever they feel a need to clean up their systems.
We can be more accurate in identifying suspicious drives if we look for multiple clues on the same drive, much as analysts look for multiple clues to confirm hypotheses (Hollywood et al, 2004). We can add suspiciousness of individual clues to get an overall suspiciousness of a drive.
3 The experimental testbed
We have been experimenting on the Real Drive Corpus (RDC) (Garfinkel et al, 2009), a corpus of drives purchased as used equipment from 22 different countries. As of March 2012 we had 2310 drive images containing 40.0 million files comprising 13.7 million unique paths. Most were disks from desktops and laptops, but some were from mobile devices and some were from storage devices. They represent a variety of usage including business users, home users, and servers of several kinds, and ranged from 0 to 25 years old. For these experiments the corpus was augmented with a few drive images created specifically for testing that included deliberate suspicious behavior. Most used NTFS file systems, but some had the older Microsoft FAT system. The great majority of the drives appeared to have normal usage without any criminal or terrorist activity.
We used the Fiwalk program (Garfinkel, 2009) to extract metadata for these files including file path and name, file size, times, NTFS flags (allocated, empty, compressed, and encrypted), fragmentation status, as well as each file's MD5 hash values. 27.7% of the files in the corpus are "unallocated" or deleted.
FAT file systems modify the directory entries of deleted file by changing the first character to hexadecimal 0xE5. In addition, metadata for deleted files on all systems may also be missing its directory information. Since deleted files are of special forensic interest, we try to reconstruct the original file path in these cases when a correction is unambiguous in our corpus. Our methods found corrections for 15.9% of the relevant files in the current corpus. Additional methods could recover more of the remaining deleted file paths (Naiqi, Zhongshan, and Yujie, 2008).
3.1 File classification based on extension and directory
Quickly assessing a drive requires some statistics as to what kinds of files are on it. This requires classifying the files into semantically meaningful groups like pictures, spreadsheets, and word-processing documents. Three kinds of groups were defined based on the 22,565 file extensions (like "htm"), the 8,373 top-level directories in which the files occurred (like "WINDOWS"), and the 5,159 immediate directories in which the files occurred (like "photos"). When immediate directories are ambiguous or just arbitrary codes, we search their parent directories in succession to find one with an unambiguous group assignment. An example where this is important is Documents and Settings/Administrator/Application Data/Microsoft/Internet Explorer/Quick Launch/Show Desktop.scf where the immediate directory that explains the purpose of this file is "Application Data". Currently we assign all extensions and directories that occur at least 200 times in our corpus, and others are assigned to the category of "miscellaneous".
For grouping file extensions, we used Wikipedia's list of common extensions and the lists of www.file-extensions.org. For grouping directory names, we used common-sense knowledge for known items and we ran Google queries for unknown items. For instance, the directory names of "videos", "movies", "peliculas", "multimedia", and "my videos" all map to the "video" category of immediate directory, but "clips" does not because it could also mean an image. For the European-language words in the RDC (mostly Spanish and German) we used a dictionary (like for "peliculas"). For Asian languages we used Google Translate, but often their file paths included English words that we could exploit. Currently 8,102 extensions and directories are mapped to 77 categories. Table 1 shows the major file groups in the corpus, with percentages both before and after the filtering described in the next section.
Table 1: Percentages of major file groups in our corpus, before and after filtering for known files (of total of 40.0 million files).
| Extension |
| Graphics | 28.8%, 34.1% | None | 14.8%, 14.5% | Executable | 12.5%, 11.8% |
| Web | 5.6%, 4.7% | Microsoft OS | 5.3%, 4.2% | Camera image | 5.1%, 6.8% | Audio | 3.6%, 1.7% |
| Config- urations | 3.1%, 2.1% | Game | 2.6%, 1.2% | Non-MS document | 2.1%, 2.0% | Multiple use | 1.7%, 1.5% |
| Temporary | 1.5%, 1.8% | Links | 1.2%, 1.5% | Help | 1.1%, 1.2% | XML | 1.0%, 0.9% |
| Low frequency | 0.9%, 1.2% | Log | 0.8%, 1.1% | Program source | 0.8%, 0.6% | Microsoft Word | 0.7%, 0.9% |
| Query | 0.6%, 0.9% | Spread-sheet | 0.6%, 0.3% | Encoded | 0.5%, 0.6% | Copy | 0.5%, 0.5% |
| Database | 0.4%, 0.4% | Integer | 0.3%, 0.4% | Video | 0.3%, 0.2% | Security | 0.3%, 0.2% |
| Disk image | 0.3%, 0.2% | Present- ation | 0.3%, 0.3% | Geogra- phic | 0.2%, 0.1% | All other | 1.1%, 1.2% |
| Top directory |
| Deleted file | 27.7%, 40.0% | Program | 23.4%. 15.7% | Microsoft OS | 19.6%, 20.5% |
| Document | 13.6%, 14.0% | Temporary | 4.4%, 4.1% | Unix and Mac | 3.8%, 2.0% | Game | 3.5%, 1.8% |
| Hardware | 0.7%, 0.7% | Root | 0.3%, 0.2% | Microsoft Office | 0.1%, 0.0% | Docs. and Settings | 0.1%, 0.1% |
| Immediate directory |
| Root (mostly default) | 25.7%, 36.0% | Temporary | 15.3%, 17.3% | Operating system | 13.7%, 12.3% |
| Application | 10.1%, 8.1% | Visual images | 9.8%, 7.7% | Documents | 4.6%, 3.3% | Hardware | 3.3%, 2.3% |
| Audio | 3.1%, 1.1% | Games | 2.0%, 1.2% | Installation | 1.5%, 1.1% | Data | 1.4%, 1.1% |
| Help | 1.4%, 1.3% | Web | 1.3%, 1.1% | Logs | 1.2%, 1.1% | Program-ming | 1.1%, 0.8% |
| Security | 1.1%, 0.9% | Sharing | 0.9%, 0.9% | Video | 0.3%, 0.2% | All other | 0.6%, 0.7% |
3.2 Filtering out known files
Forensic investigators are primarily interested in user-created files. So it is useful to exclude files of the operating system, applications software, and hardware since they do not say much about the distinctive characteristics of the user. We can do this by searching for the hash codes that Fiwalk computes on the files in the set of known hash values of the National Software Reference Library Reference Data Set (NSRL, from the U.S. organization NIST at www.nist.org/nsrl). This is an extensive collection of hash values on published software and its accompanying files. 12.2 million of the files in our corpus, or 30.4%, had hash values in NSRL, though not always under the name listed by NSRL.
A weakness of the NSRL is that it currently provides hash values only from the static files supplied with software. Some important files are created once software is installed and starts running, such as default documents. We, however, can exploit our large corpus to guess likely additions to the NSRL hash values from those files that occur on more than a certain minimum number of disks in our corpus. A minimum of five occurrences worked well in our tests. It is also reasonable to eliminate files having the same name and path as other files in the corpus that do have an NSRL hash code, since these are likely to be different versions of the same file; this eliminated an additional 1.1 million of the original corpus files as being uninteresting for further analysis, giving a total reduction of 33.26%. The second percentage given in Table 1 is for after this filtering.
4 Experiments
We implemented software to test our corpus for the clues to suspicious behavior mentioned in section 3. These tools for preprocessing the metadata are part of the Dirim system first reported in (Rowe and Garfinkel, 2011). Dirim currently follows 59 steps to produce 180 analysis files.
4.1 Encryption
Encryption is an overt clue to concealment. NTFS metadata allocates bits to indicate that a file or directory is encrypted. We did not see these bits set in any of the files of our corpus. However, we did see files whose encryption was indicated by their file extension. There were 32,806 of these in the corpus after filtering known files. Drives with a significant number of encrypted files were suspicious. We also looked for encryption software that was not part of the operating system since it is not normally installed except by people with something to hide; we counted each occurrence of such software as equivalent to 20 encrypted files in the overall total as a quick way to credit it.
4.2 Suspicious file extensions
Clues to suspicious files occur in their file extensions. Unrecognized extensions longer than 4 characters are suspicious since they are generally nonstandard and an easy way to hide data and programs. An example is avgxpl.dll.prepare where extension "prepare" is nonstandard. There were 7,215 occurrences of these in the corpus after excluding accepted known ones. Double extensions can also be suspicious since the outer extension may serve to conceal the inner extension. We found 25,718 suspicious double extensions on the corpus after excluding some judged as legitimate. Links, copies, and compression extensions like "lnk", "bak", "zip", and "manifest" have legitimate double extensions to represent the object of the action, files of Internet addresses often use the periods of the address, and some legitimate periods are associated with abbreviations. A suspicious example is ActSup.dll.tag, where "tag" conceals an executable extension "dll". Drives high on the number of suspicious extensions were judged suspicious.
Rare extensions are suspicious since they are unusual use. Rarity should not be defined by the overall count in a corpus, however, because many rare extensions occur numerous times on the drives on which they are found. We thus focus on the number of drives on which an extension occur, which we define as ![]() for extension j of M extensions. Then for each disk i, average rarity of its extensions can be calculated as
for extension j of M extensions. Then for each disk i, average rarity of its extensions can be calculated as ![]() where
where ![]() is 1 if extension j occurred at least once on disk i. We got a mean of 0.0272 and a standard deviation of 0.0599 with this metric, but some values were much higher, like one drive that had a value 0.893 on 33,017 files, indicating nonstandard usage.
is 1 if extension j occurred at least once on disk i. We got a mean of 0.0272 and a standard deviation of 0.0599 with this metric, but some values were much higher, like one drive that had a value 0.893 on 33,017 files, indicating nonstandard usage.
4.3 Suspicious paths
Files can also be suspicious if they have apparent obfuscation in their paths in the form of significant numbers of punctuation marks and, to a lesser extent, digits. Examples are "program files/!$!$!$!$.mp2" which has too many punctuation marks to be honest, and
"windows/{15d372b6-e470-11da-bb68-00105a10e007}.dat" which fails to indicate what kind of data it holds unlike most Windows operating-system files. In addition, names of files and directories that start with a punctuation mark are suspicious because this is not standard English and it is an easy way to obfuscate, though there are important exceptions such as "#" and "$" (standard program prefixes) and "&#" (HTML character codes). We found 29,002 instances of this kind of apparent obfuscation in the NSRL-filtered corpus. We used the identity of the group of the immediate directory to exclude those that were frequently seen as legitimate use of automated naming: temporaries, encodings, installation files, logs, data, and security information.
Certain characters alone are inherently suspicious, such as hexadecimal codes for characters rather than standard UTF-8 or UTF-16 encoded code points, HTML-encoded code points less than U+007F (since they can be written in UTF-8 with a single byte), and code points larger than U+1000. We found 426,142, 1,765, and 786,770 instances respectively of these characters in the corpus, so the first and third are not strong clues.
We also sought directory and file names that were misspellings of common names, another way to obfuscate, and found 4,194 occurrences in the file names of the corpus. This required a 172,173-item list of common words in the corpus languages, as well as software and hardware terms, that we compiled from a range of sources. False alarms were reduced by only counting misspellings differing by one alphabetic letter that were at least 10 times less common than their properly spelled counterpart in names at least 5 characters long.
4.4 Malicious software
The presence of malicious software may indicate an attempt to distribute it. Known malicious software can be detected by running antivirus software on a disk image. Clam AntiVirus was run on a sample of our Windows drive images. It found 6874 files on a 48-disk subset of our corpus whose contents matched virus signatures. Correlation with the other suspiciousness factors was weak.
As a shortcut to signature checking, sources like www.fileextensions.org list extensions generally associated with malware like "pid", "blf", and "gbd3". We found 5,559 instances of these in our corpus, all in software directories. But many appear to be legitimate uses that either unwittingly use a malware extension or that predate the occurrence of the malware. Some file names are specifically associated with malicious software, but most use well-known or random names for camouflage.
As for development of malicious software, the developers may have model software that will have recognized signatures. If not, the occurrence of specific software associated with malware development such as Metasploit is a clue, as is the weaker clue of file extensions and directories known to be associated with software development.
4.5 Deliberate hash collisions
A clever way to conceal a file from detailed forensic inspection would be to cause it to have the same hash code as a known innocent file. This would be useful because inspectors often use hash values from NIST or other vendors to rule out uninteresting files from further analysis. This is quite difficult because of the high computational cost to find hash collisions with the standard algorithms of SHA and MD. But it is at least worth looking for such sophisticated attacks.
A benefit of our checking files against the NSRL database is that we can assemble lists of file names of files with the same hash value; a name different than the predominant name is suspicious. We counted 340,739 such files on the corpus, where a hash value occurred at least 20 times, the predominant name occurred at least 50% of the time, but the file name in question occurred only once. Drives with large numbers of such files are more suspicious. There are legitimate reasons to rename files with unique names as when copying them, but a large amount of copying can be suspicious too.
4.6 Clusters of deletions
We can seek clusters of activity at suspicious times, such as just before the drive was captured from an insurgent. To find deletion clusters, Dirim counts the deleted files (marked by the "unallocated" flag) by day of modification for each drive and subtracts the number of files created on that day. Drives that have an unusually large number of days where this number exceeds a threshold (currently 100) are suspicious. We found 5,753 instances of such days in the corpus. (Rowe and Garfinkel, 2010) discusses more of what can be detected in analysis of file times. The total number of deletions on a drive can also be a suspiciousness clue, as people engaged in clandestine enterprises have more reason to delete files than ordinary users.
4.7 Atypical drive averages
Dirim computes averages for each drive on a number of parameters obtainable from metadata, as well as counts on the file groups of Table 1. Drives atypically high or low on these statistics may be suspicious depending on the investigation goals. For instance, the following automated summary of a student-created drive shows an unusually large number of small files created in a narrow time period, indicators of suspiciousness.
Summary of drive 1457 summer11_scenario4.xml:
Temporal characterization: little-used
low_standard deviation of modification-creation
low_standard deviation of access-creation
high_standard deviation of log of length of filename
low_average filename alphabeticality
low_average filename commonality
low_standard deviation of filename commonality
high_fraction_of_Windows_OS_topdir
high_fraction_of_logs_and_backup_botdir
high_suspicious_extensions
high_suspicious_path_characters
high_rare_extensions
4.8 Atypical clusters
More detailed differences between drives can be seen by comparing their file clusters. Table 2 gives the 34 properties we found after experiments to be the most useful for clustering. The first ten are normalized by mapping onto ranges of 0 to 1 by functions of the form ![]() for ordinary properties, or
for ordinary properties, or ![]() for widely varying properties like file and directory size, where
for widely varying properties like file and directory size, where ![]() is the integral of the normal distribution with mean of 0 and standard deviation of 1,
is the integral of the normal distribution with mean of 0 and standard deviation of 1, ![]() is the mean of the property over the entire corpus, and
is the mean of the property over the entire corpus, and ![]() is the standard deviation. This transformation maps the value to its fractional rank order in the sorting set of all values assuming it has a normal distribution, and most of the properties were close to normal; it provides a quick estimate of rank order without sorting. The remaining 24 properties are unnormalized and assigned by feature vectors provided for each group in Table 1; a file's values are the weighted average of 55% of the feature vector of its extension group, 10% of the feature vector of its top-directory group, and 35% of the feature vector of its immediate-directory group.
is the standard deviation. This transformation maps the value to its fractional rank order in the sorting set of all values assuming it has a normal distribution, and most of the properties were close to normal; it provides a quick estimate of rank order without sorting. The remaining 24 properties are unnormalized and assigned by feature vectors provided for each group in Table 1; a file's values are the weighted average of 55% of the feature vector of its extension group, 10% of the feature vector of its top-directory group, and 35% of the feature vector of its immediate-directory group.
Table 2: Properties of files used in clustering them.
| Log of size | Modification-creation | Access-creation | Access-modification |
| Log of depth | Log of name length | Alphabetic fraction | Log of count of foreign characters |
| Log of frequency in corpus | Log of size of containing directory | Degree of frequent update | Degree of being user-owned |
| Degree to which relates to operating system | Degree to which relates to hardware | Whether is an executable | Degree to which relates to executable support |
| Degree to which relates to application support | Whether at root | Whether has no extension | Whether is temporary |
| Whether is encoded | Whether is a disk image | Degree to which is a document | Degree to which relates to mail |
| Whether is a presentation | Whether is a spreadsheet | Degree to which relates to the Web | Whether is a visual image |
| Whether is audio | Whether is video | Degree to which relates to programming | Degree to which relates to specialized applications |
| Degree to which relates to games | Degree to which relates to security | Whether is data |
|
Rowe and Garfinkel, 2011) describes a clustering algorithm based on K-Means clustering the files of each drive, including iterative splitting and merging of clusters, and then clustering the clusters. We have since improved performance by taking a large random sample of the entire corpus, clustering it, mapping the entire corpus to the cluster centers found, and then clustering the residual files insufficiently close to any cluster center to provide additional cluster centers.
Figure 1 summarizes the clustering found for the 837 Windows drives in our corpus by plotting the clusters by the first two principal components, where size of the circle represents the size of the cluster. The big clusters are for caches, operating-system files, and applications files. Suspiciousness is related to the size of the cluster, not its position in this display, since there are many legitimate reasons for files to have anomalous principal components. We measure suspiciousness of a drive's clusters by the average of the reciprocal of the total number of drives with at least one representative of a cluster that has a representative on the drive.
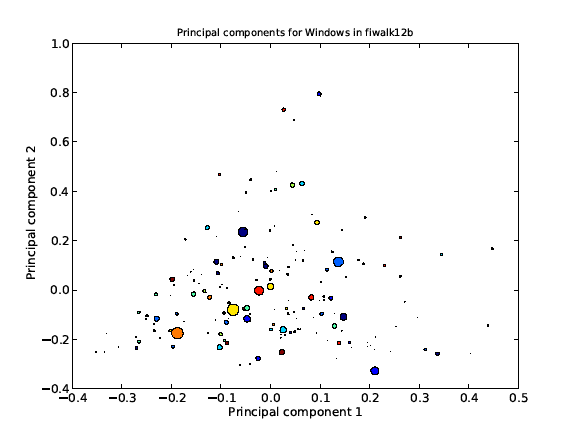
Figure 1: First two principal components of the files of the 837 Windows drives in our corpus.
4.9 Rating overall drive suspiciousness
To rate the overall suspiciousness of a drive, we can combine the abovementioned clues by taking a weighted average of their suspiciousness measures. We did experiments using the unweighted average of 15 measures on the files after filtering out known files: number of bad extensions, number of bad paths, extension rarity metric, number of misspellings, number of hexadecimal characters, number of low HTML code numbers, number of high HTML code numbers, number of files with unique names for their hash code provide another name occurred at least 10 times, number of encrypted files, number of deletion clusters, fraction of files on drive that were deleted, fraction that were email files, drive-cluster uniqueness, average file size (a negative factor), and variance in access time minus creation time (a negative factor). We took logarithms of one plus the value for the first nine since there values varied considerably between drives. We normalized the measures using the formula of the last section, and then took their average.
Figure 2 shows the histogram of overall suspiciousness for our 837 Windows drives. The mean was 0.47 with a standard deviation of 0.10. Of the test drives, the one with repeated deletions rated 0.54; the one with many encrypted messages rated 0.51; and three used in the "M57" experiments simulating more subtle malicious activity rated 0.56, 0.53, and 0.55. These values were above the mean, suggesting the drives were worth investigating. But there are too many factors here which have legitimate explanations that interfere with obtaining clearer suspiciousness ratings. The drives rated above 0.6 all had intriguing features and justify further study.
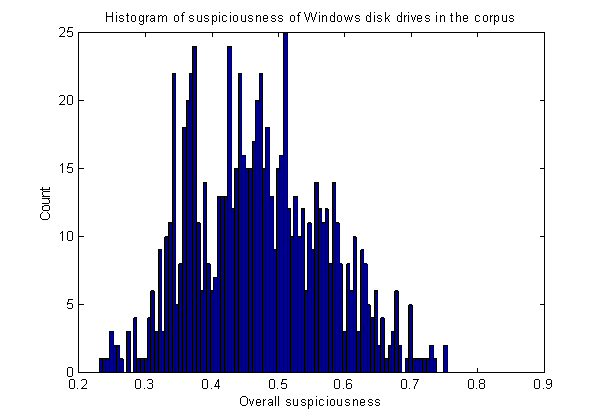
Figure 2: Histogram of the suspiciousness of the 837 Windows drives in the corpus.
.
5 Conclusions
In investigations of criminal activity, several clues can quickly distinguish a suspicious drive from an uninteresting drive using just its metadata. Certainly we can look for keywords representing targets of interest, but we can also look for general evidence of concealment and deception just in the file system. These clues may save us valuable time in directing our attention for more detailed analysis of file contents.
References
Agrawal, N., Bolosky, W., Douceur, J., and Lorch, J. (2007) "A Five-Year Study of File-System Metadata", ACM Transactions on Storage, Vol. 3, No. 3, October, pp. 9:1-9:32.
Buchholz, F., and Spafford, E. (2004) "On the Role of File System Metadata in Digital Forensics", Digital Investigation, Vol. 1, pp. 298-309.
Garfinkel, S. (2007) "Anti-Forensics: Techniques, Detection and Countermeasures," 2nd International Conference on I-Warfare and Security (ICIW), Naval Postgraduate School, Monterey, CA, March 8-9.
Garfinkel, S. (2009) "Automating Disk Forensic Processing with SleuthKit, XML and Python", in Proc. Systematic Approaches to Digital Forensics Engineering, Oakland, CA, USA.
Garfinkel, S., Farrell, P., Roussev, V., and Dinolt, G. (2009) "Bringing Science to Digital Forensics with Standardized Forensic Corpora", Digital Investigation, Vol. 6, pp. S2-S11.
Hollywood, J., Snyder, D., McKay, K., and Boone, J. (2004) Out of the Ordinary: Finding Hidden Threats by Analyzing Unusual Behavior, Rand Corporation, Santa Monica, CA, USA.
Huebner, E., Bem, D., and Wee, C. (2006) "Data Hiding in the NTFS File System", Digital Investigation, Vol. 3, pp. 211-226.
Jahankhani, H., and Beqiri, E. (2010) "Digital evidence manipulation using anti-forensic tools and techniques", Chapter 2 in Handbook of Electronic Security and Digital Forensics, World Scientific, Singapore, pp. 411-425.
Naiqi, L., Zhongshan, W., and Yujie, H. (2008) "QuiKe: Computer Forensics Research and Implementation Based on NTFS File System", in Proc. Intl. Colloquium on Computing, Communication, Control, and Management, Guangzhou, China, August, pp. 519-523.
O'Neill, P. (2010) Verification in an Age of Uncertainty: The Future of Arms Control Compliance, Oxford University Press, New York.
Pearson, S. (2010) Digital Triage Forensics: Processing the Digital Crime Scene, Syngress, New York.
Rowe, N., and Garfinkel, S. (2011) "Finding Anomalous and Suspicious Files from Directory Metadata on a Large Corpus", 3rd International ICST Conference on Digital Forensics and Cyber Crime, Dublin, Ireland, October.
Rowe, N., and Garfinkel, S. (2010) "Global Analysis of Disk File Times", Fifth International Workshop on Systematic Approaches to Digital Forensic Engineering, Oakland CA, USA, May.
This research was funded in part by NSF Grant DUE-0919593. The views expressed are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of the U.S. Government. Thanks to Hector Guerrero and Jose Ruiz. Our software and results on our corpus are freely available for further research.