Blake T. Henderson
Information Science Department
U.S. Naval Postgraduate School
Monterey, California, US
bthender@nps.edu
Sean F. McKenna
Computer Science Department
U.S. Naval Postgraduate School
Monterey, California, US
smckenna4@gmail.com
Neil C.
Rowe
Computer Science Department
U.S. Naval Postgraduate School
Monterey, California, US
ncrowe@nps.edu
Abstract - We are building honeypots for
document-collecting spies who are searching the Web for intelligence
information. The goal is to develop tools for assessing the relative
degree of interest elicited by users in representative documents. One
experiment set up a site with bait documents and used two site-monitoring
tools, Google Analytics and AWStats, to analyze the traffic. Much of this
traffic was automated ("bots"), and showed some interesting differences in the
retrieval frequency of documents. We also analyzed bot traffic on a similar
real site, the library site at our school. In nearly one million
requests, we concluded 64% were bots. 46 did identify themselves as bots,
40 came from blacklisted sites, and 12 gave demonstrably false user
identifications. Requestors appeared to prefer documents to other types
of files and 40% of the requests did not respect the terms of service on access
provided by a robots.txt file.
Keywords - honeypots, espionage, implementation, monitoring,
Web sites, analytics
I. Introduction
Cyber spies can use the anonymity of Internet personas to
steal data without attribution. Usually network defenders learn of a
spy's origin and interests only after a successful compromise. However,
honeypots allow us to set up a test environment in which we can safely monitor
the activity of network intruders and control the content they access [1, 2, 3].
Honeypots allow cost-effective collection of information on attackers over an
extended period by playing a long-term game [4]. They can also distract
intelligence collectors from legitimate resources at low cost.
A Web-based honeypot can provide a platform for
counterintelligence against adversary spies collecting information. Deception
strategies for information systems are beneficial today just as they have been
in traditional warfare [2]. Counterintelligence and deception efforts do
not replace information security, but enhance the overall security posture in
the long run [5].
II. A Honeypot for
Finding content interests of spies
A. Previous
Honeypot Research
Honeypots are digital resources without production
value, so no one should be communicating with them [1]. Honeypots are
flexible tools that can be low-interaction, medium-interaction, or high-interaction
[6]. We used a restricted form of high-interaction honeypots in our
experiments, honeypots which provide access to real operating systems and
provide the ability to collect the highest amount of information about an attack.
An early precedent honeypot was created at AT&T Bell
Laboratories [7] using a simulated system ("sandbox") to learn more about the
attacker. When the attacker attempted to erase files on the simulated
system, it provided tempting files and observed that this did not deter the
attacker. [8] emulated an institution news website containing software
vulnerabilities and had multiple pages with false information and fake articles.
They also created a Facebook page that was accidentally liked by the attacker
if he or she was logged into their Facebook account when they visited the
honeypot. They noted that users of the same language as the fake website
botnets were easier to attract. Another project [9] ran an SSH server with
a deliberate vulnerability of weak passwords. They concluded that most
activities were trying to compromise systems for use in botnets. Another
project automated the creation of fake documents called Canary Files that were
placed among real documents to aid early detection of unauthorized data access,
copying, or modification [10]. None of these projects, however, set up
sites that appeared to be run by government organizations, and these could be
more interesting to most spies.
B. Setting
Up a Document Honeypot
We created a webserver with what appeared to be a Naval
Postgraduate School address and monitored its traffic. More details are
provided in [11]. We were curious if there was any systematic collection
of information from Naval Postgraduate School websites. We could not use
an actual Naval Postgraduate School domain name, so we tried to convince users
of our website's authenticity by closely mimicking the format of actual school
library websites. We also created links from legitimate Naval
Postgraduate School webpages that redirected users to the honeypot
website. We placed the links in locations that would be found only by
someone scraping the official library and faculty webpages.
We selected content in fields of interest for cyber spies
that are covered by the Department of Defense and the Naval Postgraduate School.
We selected air, space, cyber, military science and technology, surface
warfare, subsurface warfare, special military operations, weapons systems,
declassified projects, military budgets, and military policy. We selected
132 documents to host on our honeypot website. Each of the eleven
categories contained ten to fourteen unclassified documents. Most had
been published within the last five to ten years, but some
declassified-projects documents were older because of United States government
policies on document classification. Some of these had been sanitized of
sensitive information prior to public release. All documents used in our
research were unclassified and publicly available, so we were not releasing any
sensitive information on our site.
Because the Naval Postgraduate School is a research
university, we selected technical and scientific documents within each field.
We also selected documents about recent and future Department of Defense budget
plans, and policy documents that highlighted foreign policy challenges with China
and Russia. By aggregating the documents on a web server associated with
the Naval Postgraduate School, we suggested Department of Defense interest in
these subjects and value to potential intelligence collectors.
For the experiment, we installed a Linux 64-bit Ubuntu
operating system and Apache 2.4.18 HTTP server software on a Dell Optiplex 960
desktop computer with 3 GB of RAM and a 312 GB hard disk. We opened port
80 for web traffic and port 22 for administrative SSH connections. We
used a 19-character password to reduce the vulnerabilities of an SSH
compromise, and made regular operating-system updates. We hosted the
honeypot website on an IP address within the block of addresses owned by the
Naval Postgraduate school so that a "whois" IP lookup supported our IP's
authenticity. We could not use an authentic Naval Postgraduate school URL
ending in @nps.edu, but chose the domain www.nps-future-research.org.
We used 13 different HTML files to index our hosted content
on the web server: an index file, a site map, and one file for each of the 11
document categories. To suggest legitimacy, we used the same website
header and footer as real sites at the Naval Postgraduate School and provided
links to real School webpages. We worked with a School web-services
librarian to ensure our honeypot website had a similar look and function to the
real library websites. Each category heading was a clickable link to
subpages where we hosted the honeypot documents. To encourage further
honeypot exploration into our subpages, we included a brief description of each
category on the homepage. Each subpage had functioning links to real
Naval Postgraduate School library webpages. We stored the documents as
PDF files.
To make it easier to find our honeypot, we registered our
domain name with Google so that Googlebot would index our it for the Google
search engine. Then we created a structured sitemap to enable
search-engine crawlers to find and index our webpage content, subpages, and
hosted documents.
C. Traffic-Data
Collection
We used Google Analytics [12] and AWStats [13] to
track and record interactions with our honeypot website. Google Analytics
is a popular free web-analytics software suite that tracks website usage.
It provides information on which pages users interact with the most, how long
they spend on each page, from what page the user found the website, and general
user geographic information. Google Analytics does not collect any
personally identifiable information and strips the user's IP address. It
presents the data as statistics to identify trends and patterns with website
interaction. We added a Tracking ID to the honeypot homepage and subpage
HTML files to enable the Google Analytics server to log interaction with it.
Additionally, we created an event trigger to record each time a PDF file was
downloaded so that we could analyze which were the most popular. Google
Analytics attempts to exclude Internet bot traffic to help website
administrators focus on actual user interaction.
We also used AWStats to analyze honeypot interactions
and file downloads. AWStats is a free analytic tool that assists website
administrators in examining webserver-generated log files to determine the
number of website visitors, visit duration, most viewed pages and files, HTTP
errors, and general user geographic information. Because AWStats pulls
data from the webserver logs, it does not distinguish human users from bots.
Additionally, AWStats cannot fuse different statistical data sets like Google
Analytics can. For example, Google Analytics could provide statistics
regarding which file was the most popular among users of a certain country,
whereas AWStats could provide only the file that was the most popular and the
country that accessed the website the most.
D. Results
We ran the honeypot for five and a half months. AWStats
reported that the home page represented 91.1% of page views. Beyond that,
Figure 1 and Table 1 show the ten most downloaded documents according to Google
Analytics and AWStats. The two report different results because Google
Analytics excludes automated traffic ("bots") and AWStats does not, and most of
the traffic was bots. Nonetheless, both show that a wide variety of
documents are being retrieved, both technical and policy. The aerobots
document is probably the most popular according to Google because its category
of "Air" was listed first in alphabetical order on the site; but it did not
appear that many bots and users consistently sample the page in the order of
listed links. We also saw 87 page requests trying to use our site was a
proxy, mostly to Chinese sites; Apache requires sites to accept proxy requests,
so we substituted our home page in response.
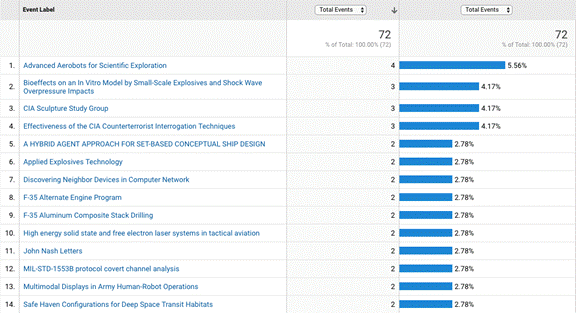
Figure 1: The top 10 visits according to Google
Analytics.
Table 1: The top 10 visits according to
AWStats.
|
Category
|
Top 10 Visits
|
Sum of
Hits
|
Sum of In-
complete Hits
|
|
Science & Technology
|
Multi-Task Convolutional Neural Network
for Pose-Invariant Face Recognition
|
591
|
328
|
|
Surface
|
Hydrostatic and hydrodynamic analysis of
a lengthened DDG-51
|
207
|
104
|
|
Surface
|
DDG-1000 missile integration
|
182
|
211
|
|
Policy
|
China's evolving foreign policy in Africa
|
149
|
10
|
|
Surface
|
Establishing the Fundamentals of a Surface
Ship Survivability Design Discipline
|
130
|
220
|
|
Special Operations
|
Roles of Perseverance, Cognitive Ability, and
Physical Fitness - U.S. Army Special Forces
|
128
|
19
|
|
Surface
|
A Salvo Model of Warships in Missile
Combat Used to Evaluate Staying Power
|
110
|
411
|
|
Cyber
|
MIL-STD-1553B protocol covert channel analysis
|
109
|
72
|
|
Policy
|
Analysis of government policies to support
sustainable domestic defense industries
|
92
|
16
|
|
Policy
|
Russia's natural gas policy toward Northeast Asia
|
89
|
421
|
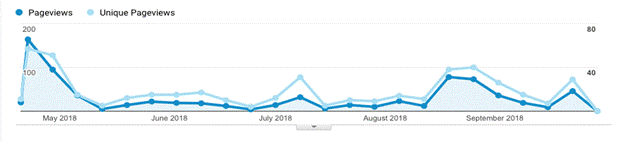
Figure 2 shows the rate of page views over time according to
Google Analytics. The initial burst of activity is typical of new
honeypots. The subsequent traffic swells illustrate the burstiness of
most Web traffic, and probably reflect "campaigns" of malicious activity.
AWStats had mostly similar trends over time, but showed a peak of activity in
June (2406 in June and 1158 in July) so June must have reflected a campaign.
Within six weeks of activating our honeypot website,
search-engine queries for "nps future research" moved from the fifth page of
results to the top result in Google queries. Apparently activity on the
site convinced Google it was legitimate, so this probably affected measured
activity.
Figure 2: Rate of page views over time on the
honeypot.
Visitors to our site were quite international, with 26% from
the United States, 24% from Brazil, 11% from China, 10% from Russia, 7% from
India, 5% from Indonesia, 5% from Turkey, 4% from Mexico, 4% from Iran, and 4%
from Italy. Google Analytics did a better job than AWStats at identifying
countries, as interpreting the AWStats data required a considerable amount of
manual lookup of IP addresses.
We also conducted tests with human subjects (some at the
school and some not) where they viewed our Web resources. In survey results
afterwards, 64% assumed the School owned and maintained the honeypot site, so
it appeared to be convincing. They were most interested in the Cyber
documents and a document from the category on sharing sensitive
network data was the most popular document among
human subjects, different from the automated visitors.
III. Analysis of Web
Bots on a Library Site
The previous work suggested that bot traffic deserves more
attention. Although bots are valuable tools for indexing content on the
Web, they can also be malicious in phishing, spamming, or performing targeted
attacks. Our detection model for malicious bots was based upon the observation
that they do not consider a resource's visibility on the Web page when
gathering information. We performed tests on a real library website at
our School. More details are in [14].
Systems would like to recognize bots, and traditionally a form
of Turing Test is given to a website's visitor to decide whether they are human.
The best-known of these are CAPTCHAs (Completely Automated Public Turing Tests
to Tell Computer and Human Apart). But the tests are not perfect, and if
they are too difficult, users will get discouraged and terminate the session
[15]. Researchers have also used log-analysis techniques for bot
detection, including machine-learning algorithms [16, 17]. [15]
introduced probabilistic modeling methods for this task. Research looking
at Web traffic on college Web servers found that Web bots requested different
resources than humans [18]. Bots had a higher preference for document
files (xls, doc, pt, ps, pdf, dvi), Web-related files (html, htm, asp, jsp,
php, js, css), and files with no extensions. Our experiments examined document
and Web resources in a honeypot.
A. Experimental
Methodology
Following discussions with the information-technology staff
at our school, we tailored honeypot content for bots that are harvesting email
addresses, often done for spam purposes. The staff were interested in
knowing whether Web bots were looking specifically for email addresses with military
domains. We created files of the three most popular content types (pdf,
doc, html) to be linked from Web pages. A third of these files contained
test military email addresses within the text, another third contained only
regular email addresses, and another third contained only text.
To show that honeypots can be used as a part of a larger
intrusion-detection or intrusion-prevention framework, we created a "sandtrap" script
to capture bot resource requests. We initially monitored JavaScript commands
but most Web crawlers in our test did not use it. We thus implemented a
server-side PHP script to catch crawlers because the School site was developed
in PHP. Our PHP code logged the time, IP address, and user agent of the
visitor. Many websites have terms-of-service agreements that explicitly
forbid crawling the site without the permission of its owner, as specified in a
robots.txt file [18]. To test this, we created such a file.
A common method for Web searching is to match the query to
the anchor text of the page link [19]. Anchor text is text in a hyperlink
that is viewable and clickable. For our test we wanted our honeypot to
attract Web bots looking for email, so we fashioned anchor text to include the
kinds of email addresses listed in the documents and pages (John.doe@navy.mil,
jane.doe@gmail.com). Our assumption was that if crawlers focused on
harvesting email addresses visited the honeypot, they would assign its links a
higher priority.
B. Crawler
Test
We ran a preliminary test using six popular Web crawling and
scraping programs: Import.io, iRobotSoft, 80Legs, ScrapeBox, and Web-scraping
frameworks in the Python and Ruby programming languages. We replicated
the School library homepage "libsearch" and installed the VuFind open-source
library portal program that the School uses. Links to honeypot resources
were placed in two hidden div layers within the header template on the test
site's index.php. One div layer contained links to the restricted area
(the "class" folder), and another contained the links to the non-restricted
area (a "noclass" folder). We embedded the two hidden div layers in the
header template of every webpage of library's libsearch.nps.edu website.
The honeypots were placed within the VuFind application directory that included
the interface for the website. The School library's site did not have a
robots.txt file, so we added ours to the website's root directory. It
included only one directive which restricted crawling of files within the class
folder.
The libsearch.nps.edu website has some characteristics of a
"deep-Web" site as it is structured to display most content through its search
interface. For a Web bot to access this content, it must generate queries
to the website's search form in its requests. The honeypot resources we
placed within the website could not detect this querying, but by placing the
honeypot resources within the header portion of the site's template, we ensured
they were accessible from the resulting page of a search query.
Test results are summarized in Table 2. All but one of
our Web crawlers fetched some honeypot resources in their crawls despite being
prohibited from doing so. The Selenium crawler was specifically designed
to avoid page elements which were hidden from view and succeeded. However,
since Selenium must execute with an active browser running, it was unclear
whether it could be run efficiently in a large-scale data-mining campaign.
All but one of the crawlers could not parse pdf files and half of the crawlers
we tested could not parse doc files.
Table 2: Summary of resources accessed by
crawlers in baseline test.
|
Program
|
Robots.txt
|
Allowed Resource
(class)
|
|
|
Banned Resource
(noclass)
|
|
Checked
|
pdf
|
doc
|
.html
|
pdf
|
doc
|
.html
|
|
Import.io
|
No
|
No
|
Yes
|
Yes
|
No
|
Yes
|
Yes
|
|
80Legs
|
Yes
|
No
|
No
|
Yes
|
No
|
No
|
No
|
|
Scrapy
|
No
|
Yes
|
Yes
|
Yes
|
Yes
|
Yes
|
Yes
|
|
Selenium
|
No
|
No
|
No
|
No
|
No
|
No
|
No
|
|
ScrapeBox
|
No
|
No
|
Yes
|
Yes
|
No
|
Yes
|
Yes
|
|
iRobotSoft
|
No
|
No
|
No
|
Yes
|
No
|
No
|
Yes
|
|
Anenome
|
No
|
No
|
Yes
|
Yes
|
No
|
Yes
|
Yes
|
|
|
|
|
|
|
|
|
|
|
Analysis of the access logs indicated that the anchor texts
did not encourage our crawlers to download one type of file more frequently
than another. We were also unable to customize crawls to search for email
addresses with either .mil or .com. extensions. This was expected
because we did not see any evidence that the tools we tested employed focused
search methods in their crawling algorithms.
C. Usage
Monitoring Results
Web logs from the libsearch.nps.edu Web server for a
five-week period provided the main data for our analysis, and sandtrap logs
provided supporting data. The data considered for our log analysis were
HTTP transactions recorded to the Web server's logs which were also in Apache
access logs. HTTP requests averaged 27,373 per day. We extracted
Web traffic from the logs with the Splunk [20] data-analysis program. Table
3 summarizes the traffic.
Table
3: Summary of Libsearch Web logs.
|
|
Human Traffic
|
Robot Traffic
|
|
Total Requests
|
334,673
|
596,028
|
|
Average Req/Day
|
9843
|
17530
|
|
Bandwidth Consumed (GB)
|
179.74269
|
39.4557
|
|
% of Distinct Requests
|
35.955 (36%)
|
64.040 (64%)
|
To distinguish humans and bots, we analyzed the "User-Agent"
field of the HTTP headers with Splunk's built-in keyword list for finding
bots. This could find the self-identifying bots, but forging this
information is simple. 46 self-identifying bots visited the website
during this period from 505 different IP addresses. The three major
search engines of Bing, Yahoo and Google accounted for 99% of the search
requests. 67% of the bot traffic requests consisted of search queries to
the /vufind/Search/Results? page.
During testing there were 358 requests for honeypot files on
the nps.libsearch.edu Web server. Of the requested files, 216 of them
were for contents within the unrestricted noclass folder, and 142 requests
(40%) were for content within the restricted class folder. Web bots
preferred document resources (doc files) more than Web resources (php and html).
This contrasted with the findings of [18] which found the opposite preference.
There were no significant differences in the number of requests for resources
containing civilian email addresses versus resources containing military email
addresses. Thus we saw no campaigns to mine military documents.
For the unrestricted noclass folder, we observed 21 Web bot
campaigns from 59 IP addresses accounting for the 216 HTTP resource requests.
A DNS lookup of these IP addresses revealed that 11 of these bots, or 52%, used
forged user-agent strings. 10 of the 11 represented Web browsers and one
represented a Google Web bot. All 10 self-identified bots checked the
robots.txt file. 2 of the 11 bots with forged user agents checked the
robots.txt file.
For the restricted class folder, we observed 16 Web bot
campaigns from 25 unique IP addresses accounting for 142 HTTP resource request.
All 25 of the IP addresses were also in the unrestricted IP list. Seven
of the campaigns were self-identified as bots, and a DNS lookup reveal 6 to be
accurate with one forged Google bot. The remaining 7 IP addresses used
forged user-agent fields representing various Web browsers. Only seven of
the 16 bots that accessed resources in the class folder checked the robots.txt
file. Of the 12 self-identifying bots, only Yandex (a Russian product) was
a well-known search engine. During the experiment, Yandex bots made 548
requests from 13 different IP addresses to the Web server, which accounted for
0.09% of the total bot traffic on the website. By our classification
scheme, all 25 of these bots were classified as "bad" by not following the
site's exclusion protocol.
We used the http:BL service from the Project Honeypot
organization to verify our results from our honeypot test. It maintains a
list of IP addresses of malicious bots that are known to harvest email
addresses for spam and other purposes [18]. The lookup found 40 IPs from
the Project Honeypot's blacklist which accounted for a total of 444 requests on
the library's Web server. However, our list of 84 IP addresses of bots
that requested honeypot resources had no matches to the Project Honeypot list.
IV. Conclusions
Intelligence gathering is facilitated by the World Wide Web.
We have shown that it suffices to monitor this activity with a few simple tools.
Creating interesting documents is important for human counterintelligence, but
bot activity appears to be quite scattered over topics, suggesting that most retrievals
are done by relatively indiscriminate bots that conceal the real interests of
human users. Thus, attempts to offer bait were ineffective. Results
also showed that content-specific anchors were useful in detecting bots, and
that bots often did not often respect site terms of service. It is clear
that espionage is easy on the Web and does not much require humans in the loop,
but at the same time it appears easy to fool intelligence gathering with
honeypots.
V. References
[1] L. Spitzner, Honeypots:
Tracking Hackers. Reading, MA, US: Addison-Wesley, 2003.
[2] N. Rowe and J.
Rrushi, Introduction to Cyberdeception. New York: Springer, 2016.
[3] N. Rowe, "Honeypot
deception tactics," in Autonomous Cyber Deception: Reasoning, Adaptive
Planning, and Evaluation of HoneyThings, E. Al-Shaer, J. Wei, K. Hamlen, and C.
Wang (Eds.). Chaum, Switzerland: Springer, 2018, pp. 35-45.
[4] J. Zhuang, V.
Bier, and O. Alagoz, "Modeling secrecy and deception in a multiple-period
attacker-defender signaling game," European Journal of Operational Research,
203(2), 2010, pp. 409-418.
[5] S. Bodmer, M.
Kilger, G. Carpenter, and J. Jones, Reverse Deception: Organized
Cyber Threat Counter-Exploitation. New York: McGraw-Hill, 2012.
[6] R. Joshi and A.
Sardana, Honeypots: A New Paradigm to Information Security. Boca Raton,
Florida: CRC Press, 2011.
[7] B. Cheswick, "An
evening with Berferd in which a cracker is lured, endured, and studied. In
Proc. Winter USENIX Conference, 1992, pp. 163-174.
[8] S. Djanali, F.
Arunanto, B. Pratomo, A. Baihaqi, H. Studiawan, and A. Shiddiqi,
"Aggressive Web application honeypot for exposing attacker's identity," 2014,
pp. 212-216.
[9] V. Nicomette, M.
Kaaniche, E. Alata, and M. Herrb, "Set-up and deployment of a
high-interaction honeypot: experiment and lessons learned," Journal in Computer
Virology, Vol. 7, No. 2, 2011.
[10] B. Whitham, "Automating
the generation of fake documents to detect network intruders," International
Journal of Cyber-Security and Digital Forensics Vol. 2, No.1, 2013, p.
103.
[11] B. Henderson, "A
Honeypot for Spies: Understanding Internet-Based Data Theft," M.S. thesis, U.S.
Naval Postgraduate School, December 2018.
[12] Google, "Google
Analytics," retrieved from analytics.google.com/ analytics/Web,, October 17,
2018.
[13] AWStats, "AWStats
official Web site," retrieved from awstats.sourceforge.io,
October 17, 2018.
[14] S. McKenna,
"Detection and Classification of Web Robots on Military Web Sites," M.S. thesis,
U.S. Naval Postgraduate School, March 2016, retrieved from
http://faculty.nps.edu/ncrowe/oldstudents/28Mar_
McKenna_Sean_thesis.htm,
October 22, 2018.
[15] A. Stassopoulou
and M. Dikaiakos, "Web robot detection: A probabilistic reasoning
approach," Computer Networks, Vol. 53, No. 3, February 2009,
pp. 265-278.
[16] D. Doran and S.
S. Gokhale. "Web robot detection techniques: overview and limitations,"
Data Mining and Knowledge Discovery, Vol. 22, No. 1, 2009, pp.
183-210.
[17] D. Doran,
"Detection, classification, and workload analysis of Web robots," Ph.D. dissertation,
Dept. Comp. Sci., Univ. of Connecticut, Storrs, CT, US, 2014.
[18] D. Doran, K
Morillo, and S. Gokhale, "A comparison of Web robot and human requests," Proc.
IEEE/ACM International Conference on Advances in Social Networks Analysis and
Mining, Niagara, ON, CA, 2013, pp. 25-28.
[19] S. Batsakis, E.G.
Petrakis, E. Milios, "Improving the performance of focused web
crawlers,, Data & Knowledge Engineering, Vol. 68, No.10, 2010,
pp.1001-1013.
[20] W. Di, L.
Tian, B. Yan, W. Liyuan, and Li Yanhui, "Study on SEO monitoring
system based on keywords & links," Proc. 3rd IEEE Intl.
Conf. on Computer Science and Information Technology, Chengdu, China
2010, pp. 450-453.