Chapter Three
Attribution of Cyber Warfare
Neil C. Rowe
[This is chapter 3 in Cyber Warfare: A Multidisciplinary Analysis, ed. J. Green, Routledge, scheduled publication 2015.]
Introduction
When I discuss the planning of cyber-attacks on the United States by other states, the usual reaction of military officers is: 'why can't we attack them back?' Usually counterattack is a key strategy and tactic in warfare, providing an important deterrent against attacks, but it is hard to do in cyber warfare. In part, this is due to the difficulty of assessing the damage of cyber-attacks and the difficulties of controlling a cyber-counterattack (Rowe, 2010). An even more significant problem, however, is determining who attacked you and proving it to the world (Goel, 2011).
The United States recently indicted some alleged Chinese hackers for stealing important business secrets by cyber espionage (Nakashima, 2014) but proving these allegations will be very difficult because of the ease of faking data in cyberspace. Proving responsibility for cyber warfare is a similar problem. On the other hand, when the Russian army invaded Crimea in 2014, Russia's initial denial of involvement did not convince anyone since it was the only neighbouring state and the invaders were speaking Russian. Similarly, when aircraft drop munitions on another state, their flight paths can be traced and usually a single state can be identified as their source. Attribution in the context of cyber warfare presents unique difficulties that are not apparent in other conventional means and methods of armed conflict.
Several factors contribute to the difficulty of cyber warfare attribution:
- Cyber weapons have considerably more variety than conventional munitions, since there are many ways that computers and networks can be disabled. This means that searching for cyber weapons and their use is considerably harder than searching for other kinds of weapons and their use.
- Cyber weapons do not require physical proximity of the attacker to the victim (Brenner, 2007). Since information is automatically and quickly forwarded on the Internet to wherever it needs to go, it is almost as easy to cyber-attack a site on the opposite side of the world as a geographically proximate site.
- Cyber-attacks will be unlikely to come with intrinsic attribution data, unlike uniforms for military personnel and markings for military vehicles.
- Cyber weapons do not leave persistent traces like chemical residue, fingerprints, or perpetrator DNA since digital data can be easily overwritten to leave no trace of the original data.
- Cyber weapons are easy to conceal since they are just abstract patterns of bits, looking just like legitimate data and programs until subjected to detailed inspection. This means they can easily be trafficked across the Internet, making them accessible to small or less powerful states, as well as terrorist groups.
- Cyber weapons can easily implement delayed effects after they are installed, waiting for the right conditions or specified times to act. This means that the relationship between cause and effect of a cyber weapon can be difficult to see.
- Cyber weapons technology is very similar to cyber espionage technology: The main challenges for both are to gain access to adversary computer systems and establish a foothold. This means that it is difficult to distinguish counterattack-justifying behaviour from routine espionage.
These difficulties in attribution make cyber weapons appealing for many countries, and suggest that we will see increasing use of such weapons by nation-states (Geers et al., 2013). Despite the abovementioned difficulties, attribution of cyber-attacks is definitely possible. The evidence will always be circumstantial in the legal sense since cyber-attacks cannot be witnessed inside computers directly. Nonetheless, strong legal cases can be made from circumstantial evidence, and much progress has been made in the techniques of data mining from computer science (Mena, 2003) to construct such cases.
Attribution of Files
One approach to attribution is to examine the artefacts left in a computer or digital device that is the victim of a cyber-attack. Legitimate software usually contains attribution information to provide recourse for the end-users of faulty products. But even without explicit attribution, we may recognize malicious software ('malware'). Anti-malware software that identifies known malware is widespread, and libraries of malware are available such as the Open Malware site (oc.gtisc.gatech.edu:8080) for which matches can be quickly found using the hash values for the entries. A hash value is a many-to-one mapping from a set of bits to a much smaller set of bits, and is often used for indexing data. We may also be able to recognize parts within malware even when we do not recognize their whole; cyber warfare specialists within each state will tend to reuse some code sequences because it saves time and improves attack effectiveness. We can identify pieces of code through subfile hashing methods (Garfinkel et al., 2010) and we can recognize overall similarities through functional analysis of the code (Aquilina, Casey and Malin, 2008). We can also undertake stylistic analysis of cyber-attack programs or data (Kothari et al., 2007; Rosenblum, Miller and Zhu, 2011), analogous to stylistic analysis of prose, to get clues to authorship. This can allow us to find similar coding patterns such as proportions of certain kinds of instructions or sequences. This was used to establish sources within Russian organized crime of some of the cyberattacks on Georgia in 2008 (USCCU, 2009).
Once we have established similarity between new malware and previous malware, we can guess that an attribution to the previous malware will also apply to the new malware. Given sufficient time, most previous malware is thoroughly investigated and a good deal is learned about it, including its origins. However, identifying a similarity between malware only provides a probability of authorship rather than a certainty, and this does not prove attribution since a person or state can buy or steal another's malware.
Attribution is much more possible if we can obtain a computer or device (and its peripheral devices, since they often have most of the data) that we suspect is responsible for the planning or execution of a cyber-attack (such as by seizing it in a military operation). We may then be able to match the malware used in the attack to malware on the computer or device, or examine the logs of activity on the computer to show that the attack was launched from there. This provides strong evidence of responsibility for an attack, particularly if the malware is unusual or we also find tools for controlling and testing malware. We can also find user names and other personal identifying information to indicate who was using the computer or device, to enable us to possibly hold them legally, or politically, responsible.
Attribution of Network Traffic
Another approach to attribution is to examine network traffic to see where an attack is coming from. Internet traffic is comprised of 'packets' of information. While there are many protocols, the common IPv4 protocol is typical. IPv4 packets specify in order the type of software the packet supports, the packet length, subpacket information if the packet has been split, 'time to live' or number of forwardings allowed, the protocol used, code for error detection, the source address, the destination address, additional options, and the actual data transmitted. Only the source address gives information about where the packet is from, in the form of an 'IP address' given as four 8-bit numbers. This was originally supposed to be the address of the computer sending the packet, but since there are more computers than possible addresses in IPv4, it is often the address of a proxy server that handles many customers simultaneously. It is not difficult to fake ('spoof') an address since packets generally pass through many routers on their way across the Internet, and routers could deliberately change the packets to conceal their origins. In fact, 'anonymizers' for the Internet like Tor (www.torproject.org) do this for legitimate purposes such as protecting user privacy when browsing. It is very likely that deployers of cyber weapons, similarly to cyber criminals, will falsify their originating sites since otherwise automated responses can quickly thwart control of the attack by blocking traffic from there. That means the direct method of attribution of checking packet source addresses will fail for cyber weapons.
Backward Tracing of Traffic
To check if an Internet address has been spoofed in packets, it is helpful to immediately attempt to contact the alleged address with a simple request such as a ping or 'are-you-there' request. If the site does not respond, or responds with a packet ID number or time-to-live value that is very different from that of the original packet, that suggests spoofing (Templeton and Levitt, 2003). Routers also can recognize some spoofing directly because they can know when the last-given source address is external to a local-area network and could not be correct. Other kinds of spoofing can be inferred if one knows the rules by which sites forward their packets and the data provided with the packet violates those rules (Cohen and Narayanaswamy, 2004). Any spoofing that is detected is rare and suspicious activity, and warrants more detailed investigation.
Even with spoofing, we may be able to determine the true address by backward tracing or 'backtracing' the packet across the Internet. This is particularly feasible if the attack has some distinctive packets. To do it, we contact the site administrator of the last site, have them retrieve the cached origin information, contact that site in turn, and repeat until the original source is found. Records of packet data are only kept for a limited time, so backtracing needs to be done quickly after an attack. If an intermediate site has been attacked itself to facilitate the transmission of malware, contacting the site administrator is valuable help for them in indicating security problems that they need to fix.
If we can characterize a known malicious packet at the attack target, we can search cooperative Internet sites to find earlier occurrences of the same packet even without backtracing. We may be able to guess sites involved in the attack because of the data in the packet or the history of similar previous attacks, so we can start with those. Most Internet sites are cooperative with international law enforcement. The emergence of broad-area routers for regions of the world means that those router sites are good places to look for information, and they have already been directed to collect information useful for backtracing of criminal malware and scams. We are seeing increasing international cooperation on tracing of criminal activity in cyberspace starting with the Convention on Cybercrime of 2001 and including recent initiatives by Europol and NATO. Much of this cooperation will be effective in tracing state-sponsored cyber-attacks that traverse the Internet as well.
Massive attacks such as denial-of-service ones are easier to trace than single-packet attacks because they provide plenty of data. With such attacks, large portions of Internet space are commandeered, likely including some sites with good backtracing capabilities. Massive attacks can also be done with botnets, large numbers of maliciously controlled computers and devices (Elisan et al., 2012). Although the botnet computers may be scattered over the world, they need to be controlled from a central site, and the central site can usually be tracked down without much difficulty from observing the odd messages sent to and from it.
The major challenge to backward tracing and searching of sites is dealing with the huge volume of data. Carefully designed methods can speed detection of strings of interest (Haghighat, Tavakoli, and Kharrazi, 2013). It can also help to store signatures of packets or files in the form of cryptographic hash values computed on them by hash standards like SHA-1. A SHA-1 signature, 160 bits appearing to be random, is very unlikely to coincide for any two packets or files, since on the average it will take 10 to the 48th power tries to match a given signature. Another challenge is that a given signature needs to be confirmed as part of a cyber-attack to make it worth searching for, and that confirmation may take so much time that the tracing information will be lost by then.
A countermeasure to backtracing is for attackers to vary their code so the attack appears different each time: what are termed 'polymorphic' attacks. However, to reduce code writing, many of the pieces must be the same, and this common code can be recognized by subpacket or subfile hashing. In fact, large data files sent across the Internet are split into small packets anyway, so malware may well have recognizable hashes for some packets even if the attacker uses polymorphism. In addition, many attackers view mounting polymorphic attacks as undesirable, because it is hard for the different versions of the attack to recognize one another and consequently they tend to inefficiently reinfect the same machines repeatedly.
Alternatives to Backward Tracing
Even if we cannot backtrace an attack, correlation of information between attacks can be a helpful step towards later attribution. Attackers, both criminal and those engaged in cyber warfare, tend to repeat particular methods of attack (modus operandi) (Kong et al., 2013) as well as attack code. An attacker's modus operandi will often include the apparent planning for the attack, the presurveillance methods used, the type of weapon, the timing of the attack, the precautions taken by the attacker, and the volatile (main-memory) clues left (Turvey, 2011). We can develop a model from a similar set of attacks and use it to recognize new attacks from the same source, something that can be done automatically with a variety of machine-learning techniques (Pfeffer et al., 2012). Then, if we obtain additional clues, such as through catching a spy from a particular state who possesses code for a previously seen attack, we can infer that it applies to similar attacks.
Correlation can also be done with network data even if we cannot backtrace. Intermediate sites seeing earlier or large amounts of traffic for an attack are likely closer to the source than other sites (Thonnard, Mees, and Dacier, 2010), and we can combine multiple pieces of uncertain evidence to get stronger evidence (Kalutarage et al., 2012). We can also use the 'time to live.' For instance, Figure 1 shows a network. If site A receives a denial-of-service packet from site B with a time-to-live of 62, and an identical packet from C with a time-to-live of 61, then if we assume a common source for both packets, the source must be closer to B than to C because time-to-live is decremented at each step. Assuming that the initial time-to-live was 64, a common initial value, we can infer that the packet must come from E and not D, F, or G, even if the source address is being spoofed.
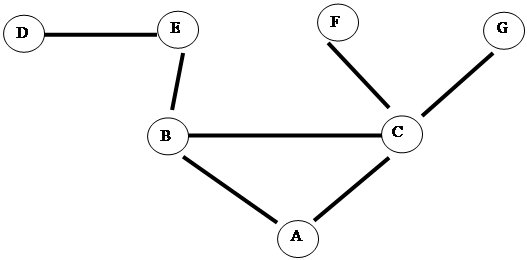 |
Figure 1: Example network
Planting Beacons
Backward tracing can be made easier if the source of the cyber-attack can be induced to provide identifying information. Cookies for Web browsing are one example, where data from a Web destination site is sent back to the browser source site to save time on subsequent reconnections (Brain, 2014). A Web site that is a victim of a cyber-attack could send back a cookie with a unique identifying code to the cyber-attacker to enable recognition of the attacker on subsequent activity, to aid in attribution. However, this only works for Web protocols, and requires the attacker to accept cookies, which they may well choose not to.
More can be accomplished if we can put specialized software onto the attacker's computer, since cookies cannot include executable code. We may be able to induce the attacker to download an executable file, particularly if they are trying to steal secret data anyway. Then, when the executable file is run, it could send messages including the name, Internet address, software present and other identifying information about the attacker site. Executables can also be sent back to an attacker by 'drive-by downloads' using techniques of malicious Web sites, or spies could also plant executables on possible attacker computers or attach wireless hardware. However, these methods would themselves be illegal in most states, going well beyond the legally acceptable responses to a crime to being cyber-attacks themselves.
A counterintelligence technique that can provide a beacon in a more legal way is to offer distinctive false information to attackers. An example is when the attacker is trying to steal something like a password; we can give them a distinctive false password, and then look for its use. Backtracing can then be focused more narrowly.
Countermeasures for beacons involve trying to detect the beacon signal and stopping it. This can be done by anomaly analysis in network outgoing network traffic. Then the beacon source can be disabled, or better, transferred to another computer to provide a decoy target. However, most attackers do not have time to do this.
Attribution to a State
The focus of this book is on cyber warfare (meaning inter-state cyber-attacks). While most of the forgoing analysis is relevant both to cyber activity by individuals and state-sponsored cyber-attacks, the particular issue of technically attributing a cyber-attack to a state is an especially pertinent one in the context of this volume. It is desirable to attribute cyberwar-type attacks to a state to enable settlement of the conflict and fair clean-up and reparations. However, even if we can attribute an attack to a particular computer or device in a particular country, we cannot necessarily attribute it to that country. And even if we have enough evidence to attribute it to a state, we need to collect evidence through carefully employing a validated 'chain of custody' and carefully documented standard procedures (Casey, 2011) so that our evidence will reach an acceptable legal standard (on the problem of attaining the legal standard of evidence for state cyber aggression, see the chapter by Green in this volume). Despite these difficulties, proving attribution of a damaging cyber-attack can be beneficial to the world community in much the same way as trials for war crimes (Ellis, 2001) and has benefits in establishing international standards of cyber conflict even if state responsibility is not sufficiently established.
Semantic Analysis of Cyber-Attacks for Attribution
One obvious clue to attribution is analysis of which states could benefit from an attack. If a state is engaged in a conventional war with another country, or is on the brink of one, then cyber-attacks are more likely to originate from the two warring parties as tactical ploys. This was the case for the cyber-attacks on Georgia by Russia in 2008, which were followed by – and continued in the ongoing context of – conventional military action. Such knowledge narrows the search over the Internet for clues; it is rather different in the case of criminal cyber-attacks, which could generally come from anywhere. However, such obvious or 'semantic' clues may be misleading, because a third party may actually be responsible and be trying to provoke a war. That is more likely to occur with cyber warfare than with traditional warfare because the low cost of mounting cyber-attacks makes them available to states with limited resources. For example, we can see a good deal of third-party involvement today in the Israeli-Palestinian conflict (Okuniewska, 2013).
Levels of National Responsibility
In many cases, a state has disclaimed responsibility for cyber-attacks because it has claimed that the responsible computers or devices within its borders were used to attack without approval of the state, as with criminal cyber-attacks. In such instances, it is the responsibility of the state in question to stop the attacker and impose penalties, much as it is responsible for terrorists within its borders (Värk, 2006; see also the chapter by Green in this volume, discussing the legal obligation of 'cyber due diligence'). If the state does not police the attacks, it is violating a key principle of international law, but this does not necessarily mean the state is legally responsible for the attacks. Healey (2011) distinguishes ten progressive levels of national responsibility for cyber-attacks: state-prohibited, inadequately-state-prohibited, state-ignored, state-encouraged (as by editorials), state-shaped (as by actively recruiting independent attackers by social networking (Johnson, 2014)), state-coordinated, state-ordered, state-rogue-conducted (as by people in the government not acting by government order), state-executed, and state-integrated (including both the government and other people). Different observers can disagree as to where in this list true national responsibility beings. Nonetheless, threshold events can be tied to this spectrum: for instance, whether a state prosecutes its citizens responsible for an attack is a good threshold event for distinguishing inadequately-state-prohibited from state-ignored attacks, and evidence from bulletin boards can distinguish state-encouraged from state-shaped attacks. Evidence from the attack computers and devices in their messages and downloads can more convincingly prove state coordination.
For widely distributed attacks such as by botnets, backtracing the botnet communications is essential to reduce the possible sources to a small number. But all the states harbouring the bots or sub-attackers should take measures to stop the attack machinery within their borders because it is stealing their resources as well, and it is in their interests to cooperate internationally to share information about the attack even if they have no legal obligation. A complicating issue is that the nationality of the owner of an attacking computer or device may not be that of the state in which they reside. However, visitors to a country are still subject to its laws.
Proving Attribution to the World Community
A key problem with attributing cyber aggression is that much of the evidence will likely be circumstantial and will not meet legal requirements for assigning responsibility (O'Connell, 2012). Thus even if a nation is entirely sure who attacked it, it may be unable to justify a counterattack for the world community. Evidence is circumstantial because data can be easily changed in cyberspace without leaving traces, through spoofing for instance. The sophistication of an attack generally does not rule out any particular states, since 'sophistication' is very much in the eye of the beholder (Guitton and Korzak, 2013) and a primitive state can buy sophisticated technology at a reasonably low cost.
Another issue is that, even if we capture a computer that was used in cyber-attacks and show by its records that it initiated the attacks, this may be insufficient legal proof because the computer records may have been modified to incriminate (FIDIS, 2006). Having said this, there are standard procedures for cybercrime investigations that should be followed, and can be similarly employed in attributing inter-state cyber-attacks. These include scripted steps for interacting with device whose accomplishment can be confirmed by log files, operating only on copies of the original data, and installing 'write blocker' software on the analysed computer to prevent tampering with evidence. If these are followed, the evidence obtained can be strong.
Illegal methods can support attribution. If someone breaks into the computer or device used to launch the attack, they can search around for evidence of who owns it. They may be able to find personal identification of the owner such as names, addresses, phone numbers, personal identification numbers and so on, and do so more easily than if the owner knows their machine is to be seized. They may also be able to find clues to government involvement in cyber-attacks. However, it should go without saying that breaking the law to investigate crimes is not acceptable in most states.
Experts may very well disagree on a question of attribution. Ranum (2011) argues that attribution questions should be decided publicly using experts from all sides of a conflict, and should use accepted, standard, and open-source methods so that the world community can be convinced. It is useless to establish attribution of a cyber-attack by secret methods because the necessary next step – proving it to the world community – would reveal the methods.
Explicit Attributability
Various proposals have been made to increase attributability of Internet activity by attaching stronger information to packets, such as requiring every computer and device to embed a hardwired identification code in its packets. However, Clark and Landau (2010) point out that these methods will not usually help against well-organized adversaries such as states engaging in cyber-attacks, since if they wish, large organizations can use sophisticated methods to conceal themselves well even with increased attribution measures. For instance, states can put their attacks into modified computer chips (integrated circuits) installed on systems, or transmit attacks to hidden receivers attached to systems, so no malicious traffic need traverse Internet connections.
Nonetheless, I have argued elsewhere (Rowe, 2010) that voluntary attributability is desirable for cyber-attacks to provide better political effects, for how can a state be effectively coerced if it does not know who is attacking it? This could be analogised to the wearing of uniforms and the placing of distinctive markings on military vehicles. Obvious indications of the source of an attack are undesirable to attach to the attack as then it could be more easily blocked. So steganography (Fridrich, 2009), or hidden data, is necessary for voluntary attributability. There are many methods: for instance, the attribution text can be hidden in every 1183rd character, or put in the lower-order bits of a picture. Attribution can be made provable later by the attacker if they provide information about the steganographic method used, and can use a cryptographic signature so it cannot be forged. However, there is a close connection between espionage and cyber warfare, and attribution is not desirable in espionage; this makes it hard for cyberwar planners to understand the value of attributability.
Conclusion
Attribution of cyber-attacks in cyber warfare is a difficult but not impossible problem. The often large scale and effectiveness of the attack provides opportunities for tracing and analysis that are not possible with the common criminal cyber-attacks we see more regularly on the Internet. Still, the evidence that we obtain will generally be circumstantial and difficult to use in legal proceedings unless computers and devices of the alleged attackers can be searched. It does not appear that this assessment will change anytime soon even with major technological changes, so the major invasions of Internet privacy that some people propose to keep us safe (e.g., those described in Angwin, 2014) appear unjustified.
Acknowledgment
This work was supported by the United States National Science Foundation under grant 1318126 of the Secure and Trustworthy Cyberspace Program. The views expressed are those of the author and do not represent those of the United States Government.
References
Angwin, J. (2014) Dragnet nation: A quest for privacy, security, and freedom in a world of relentless surveillance, New York: Times Books.
Aquilina, J., Casey, E. and Malin, C. (2008), Malware forensics: Investigating and analyzing malicious code, Burlington, MA: Syngress.
Brain, M., 'How Internet cookies work,' retrieved from computer.howstuffworks.com/cookie.htm, July 12, 2014.
Brenner, S. (2007) 'At light speed: Attribution and response to cybercrime/terrorism/warfare,' Journal of Criminal Law and Criminology, vol. 97, no. 2, pp. 379-475.
Casey, E. (2011) 'Handling a digital crime scene,' in Casey, E. (ed.) Digital evidence and computer crime, 3rd edition, Waltham, MA, US: Elsevier.
Clark, D. and Landau, S. (2010) 'The problem isn't attribution; it's multi-stage attacks,' Proceedings of Workshop on Re-Architecting the Internet, Philadelphia, PA, USA, November, Article 11.
Cohen, D. and Narayanaswamy, K. (2004) 'Attack attribution in non-cooperative networks,' Proceedings of the IEEE Workshop on Information Assurance, West Point, NY, June, pp. 436-437.
Elisan, C. (2012) Malware, rootkits, and botnets: A beginner's guide, New York: McGraw-Hill Osborne.
Ellis, A. (2001) 'What should we do about war criminals?,' in Jokic, A. (ed.), War crimes and collective wrongdoing, Oxford: Wiley-Blackwell.
FIDIS (2006, January) 'Forensic implications of identity management systems,' WP6, D6.1 [Online], Available: www.fidis.net/resources/deliverables/forensic-implications [2 July 2014].
Fridrich, J. (2009) Steganography in digital media: principles, algorithms, and applications, Cambridge: Cambridge University Press.
Garfinkel, S., Nelson, A., White, D. and Roussev, V. (2010) 'Using purpose-built functions and block hashes to enable small block and sub-file forensics,' Digital Investigation, vol. 7, pp. S13-S23.
Geers, K., Kindlund, D., Moran, N. and Rachwald, R. (2013) 'World War C: Understanding nation-state motives behind today's advanced cyber attacks,' FireEye [Online], Available: http://www.fireeye.com/resources/pdfs/fireeye-wwc-report.pdf [7 April 2013].
Goel, S. (2011) 'Cyberwarfare: connecting the dots in cyber intelligence,' Communications of the ACM, vol. 54, no. 8, pp. 132-140.
Guitton, C. and Korzak, E. (2013) 'The sophistication criterion for attribution,' The RUSI Journal, vol. 158, no. 4, pp. 62-68.
Haghighat, M., Tavakoli, M. and Kharrazi, M. (2013) 'Payload attribution via character dependent multi-bloom filters,' IEEE Transactions on Information Forensics and Security, vol. 8, no. 5, pp. 705-716.
Healey, J. (2011) 'Beyond attribution: Seeking national responsibility for cyber attacks,' Issue Brief, Atlantic Council [Online], Available: https://www.fbiic.gov/public/2012/mar/National_Responsibility_for_CyberAttacks,_2012.pdf [4 April 2014].
Hunker, J., Hutchinson, R. and Margulies, J. (2008) 'Roles and challenges for sufficient cyber-attack attribution,' Research Report, Institute for Critical Infrastructure Protection, Dartmouth College, Hanover NH [Online], Available: www.thei3p.org/docs/publications/whitepaper-attribution.pdf [7 April 2014].
Johnson, C. (2014) 'Anti-social networking: crowdsourcing and the cyber defence of national critical infrastructures,' Ergonomics, vol. 57, no. 3, pp. 419-433.
Kalutarage, H., Shaikh, S., Zhou, Q. and James, A. (2012) 'Sensing for suspicion at scale: A Bayesian approach for cyber conflict attribution and reasoning,' Proceedings of the 4th International Conference on Cyber Conflict, Tallinn, Estonia.
Kong, D., Tian, D., Pan, Q., Liu, P. and Wu, D. (2013) 'Semantic aware attribution analysis of remote exploits,' Security and Communications Networks, vol. 6, no. 7, pp. 818-832.
Kothari, J., Shevertalov, M., Stehle, E. and Mancoridis, S. (2007) 'A probabilistic approach to source code authorship identification,' Proceedings of the Fourth International Conference on Information Technology, pp. 243-248.
Mena, J. (2003) Investigative data mining for security and criminal detection, Burlington, MA: Elsevier Science.
Nakashima, E. (2014) 'Indictment of PLA hackers is part of broad U.S. strategy to curb Chinese cyberspying,' Washington Post, 22 May.
O'Connell, M.E. (2012) 'Cyber security without cyber war,' Journal of Conflict and Security Law, vol. 17, no. 2, pp. 187-209.
Okuniewska, E., 'The role of third parties in Israel and Palestine,' Palestine-Israel Journal of Politics, Economics, and Culture, May 19, 2013.
Pfeffer, A., Call, C., Chamberlain, J., Kellogg, L., Ouellette, J., Patten, T., Zacharias, G., Lakhotia, A., Golconda, S., Bay, J., Hall, R. and Scofield, D. (2012) 'Malware analysis and attribution using genetic information,' Proceedings of the 7th International Conference on Malicious and Unwanted Software, Fajardo, Puerto Rico, October, pp. 39-45.
Ranum, M. (2011) 'Cyberwar: about attribution (identifying your attacker),' 21 October, Fabius Maximus [Online], Available: http://fabiusmaximus.com/2011/10/21/30004/ [3 June 2011].
Rosenblum, N., Miller, B. and Zhu, X. (2011) 'Recovering the toolchain provenance of binary code,' Proceedings of the International Symposium on Software Testing and Analysis, Toronto, ON, CA, pp. 100-110.
Rowe, N. (2010) 'The ethics of cyberweapons in warfare,' International Journal of Technoethics, vol. 1, no. 1, pp. 20-31.
Templeton, S. and Levitt, K. (2003) 'Detecting spoofed packets,' 3rd DARPA Information Survivability Conference and Exposition, Washington, DC, USA, April, pp. 164-177.
Thonnard, O., Mees, W. and Dacier, M. (2010) 'On a multicriteria clustering approach for attack attribution,' ACM SIGKDD Explorations, vol. 12, no. 1, pp. 11-20.
Turvey, B. (2011) 'Modus operandi, motive, and technology,' in Casey E. (ed.) Digital evidence and computer crime, 3rd edition, Waltham, MA, US: Elsevier.
USCCU (United States Cyber Consequences Unit) (2009, August) 'Overview by the US-CCU of the Cyber Campaign against Georgia in August of 2008.' US-CCU Special Report, downloaded from www.usccu.org, November 2, 2009.
Värk, R. (2006) 'State responsibility for private armed groups in the context of terrorism,' Juridica International, vol. 11, pp. 184-193.